Przed przystąpieniem do realizacji zadań upewnij się, że rozumiesz mechanizm alokacji pamięci dla tablic oraz różnicę między typami referencyjnymi a wartościowymi. Zadania wymagają korzystania z przestrzeni nazw System.Collections.Generic.
UWAGA: W kodzie C# separatorem dziesiętnym jest zawsze KROPKA (.), nie przecinek! Podczas parsowania liczb rzeczywistych używaj formatu np. 12.5 a nie 12,5.
Spis treści
- Statystyki temperatury (Tablice 1D)
- Sortownik liczb (Listy i Sortowanie)
- Zarządzanie parkingiem (Tablice 2D)
- Dziennik ocen (Tablice nieregularne)
- Interaktywna lista zakupów (List<string>)
- Uproszczona gra w wisielca
- Licznik słów (Podstawy Dictionary)
- Algorytm wyszukiwania binarnego
- Sumowanie kwadratów (Pętla foreach)
- System rezerwacji biletów (Hybryda)
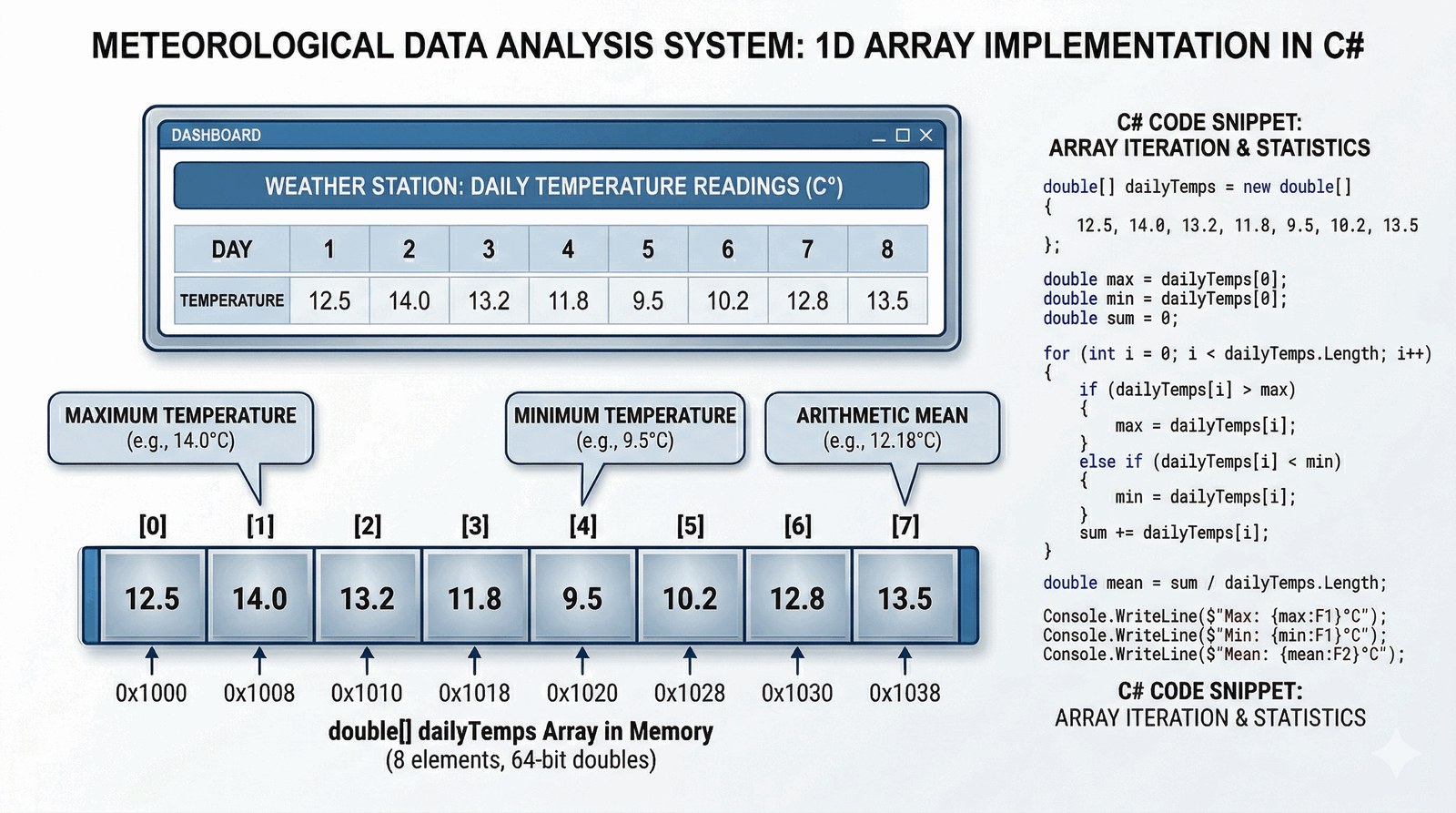
Celem zadania jest praktyczne zastosowanie jednowymiarowych tablic do przechowywania i analizy zbiorów danych liczbowych w środowisku C#. Student nauczy się efektywnego zarządzania pamięcią poprzez dynamiczną alokację rozmiaru tablicy w czasie wykonywania programu. Ćwiczenie kładzie nacisk na umiejętność iteracji po strukturach danych w celu wydobycia istotnych informacji statystycznych.
Wyobraź sobie, że pracujesz jako programista w instytucie meteorologicznym, który potrzebuje narzędzia do szybkiej analizy danych pogodowych. Twoim zadaniem jest stworzenie aplikacji, która pozwoli pracownikom terenowym na wprowadzanie pomiarów temperatury zebranych w ciągu wybranego okresu czasu. System musi być elastyczny, dlatego pierwszym krokiem jest zapytanie użytkownika o dokładną liczbę planowanych pomiarów, co pozwoli na optymalne zarezerwowanie miejsca w pamięci operacyjnej. Następnie, wykorzystując pętlę sterującą, program powinien pobrać wszystkie wartości i zapisać je w strukturze tablicowej. Po zakończeniu etapu wprowadzania danych, algorytm musi automatycznie wyznaczyć kluczowe wskaźniki: temperaturę maksymalną, minimalną oraz średnią wartość dla całego zbioru. Gotowe zestawienie statystyczne ma zostać zaprezentowane w formie czytelnego raportu konsolowego, co ułatwi podjęcie decyzji o dalszych działaniach operacyjnych instytutu. Rozwiązanie to stanowi fundament pod bardziej rozbudowane systemy monitoringu środowiskowego.
Tablice jednowymiarowe w C# są strukturami o stałym rozmiarze, które alokują ciągły blok pamięci na stercie zarządzanej. Deklaracja tablicy typu double[] wymaga użycia słowa kluczowego new, co inicjuje proces alokacji zasobów przez runtime .NET. Rozmiar tablicy jest definiowany dynamicznie w czasie wykonywania programu na podstawie wartości pobranej od użytkownika przez int.Parse(). Każdy element tablicy jest indeksowany od zera, co oznacza, że dostęp do n-tego elementu odbywa się poprzez indeks n-1. Pętla for służy do sekwencyjnego wypełniania tablicy danymi wprowadzonymi za pomocą Console.ReadLine(). Dostęp do elementów tablicy za pomocą operatora indeksowego [] jest operacją o złożoności stałej O(1). W celu analizy statystycznej wykorzystujemy pętlę foreach, która jest bezpiecznym mechanizmem iteracji po całej kolekcji bez ryzyka przekroczenia jej zakresu. Właściwość Length obiektu tablicy dostarcza informacji o całkowitej liczbie elementów, co jest kluczowe przy obliczaniu średniej arytmetycznej. Algorytm wyznaczania maksimum i minimum inicjuje zmienne pomocnicze pierwszą wartością z tablicy (temperatury[0]). Operacja suma += t demonstruje mechanizm akumulacji wartości zmiennoprzecinkowych wewnątrz pętli. Należy pamiętać, że tablice są typami referencyjnymi, co oznacza, że zmienna temperatury przechowuje jedynie adres do danych na stercie. Przekroczenie zakresu tablicy skutkuje zgłoszeniem wyjątku IndexOutOfRangeException, co wymaga od programisty dbałości o warunki brzegowe pętli. Formatowanie wyniku za pomocą specyfikatora :F2 zapewnia profesjonalną prezentację danych numerycznych z precyzją do dwóch miejsc po przecinku. Alokacja tablicy o bardzo dużym rozmiarze może prowadzić do problemów z fragmentacją pamięci w obszarze Large Object Heap (LOH). Zastosowanie tablic jest bardziej wydajne pod względem zużycia procesora niż użycie kolekcji dynamicznych w scenariuszach o znanej liczbie elementów. Całość implementacji promuje dobre praktyki zarządzania zasobami i podstawowe operacje na strukturach liniowych.
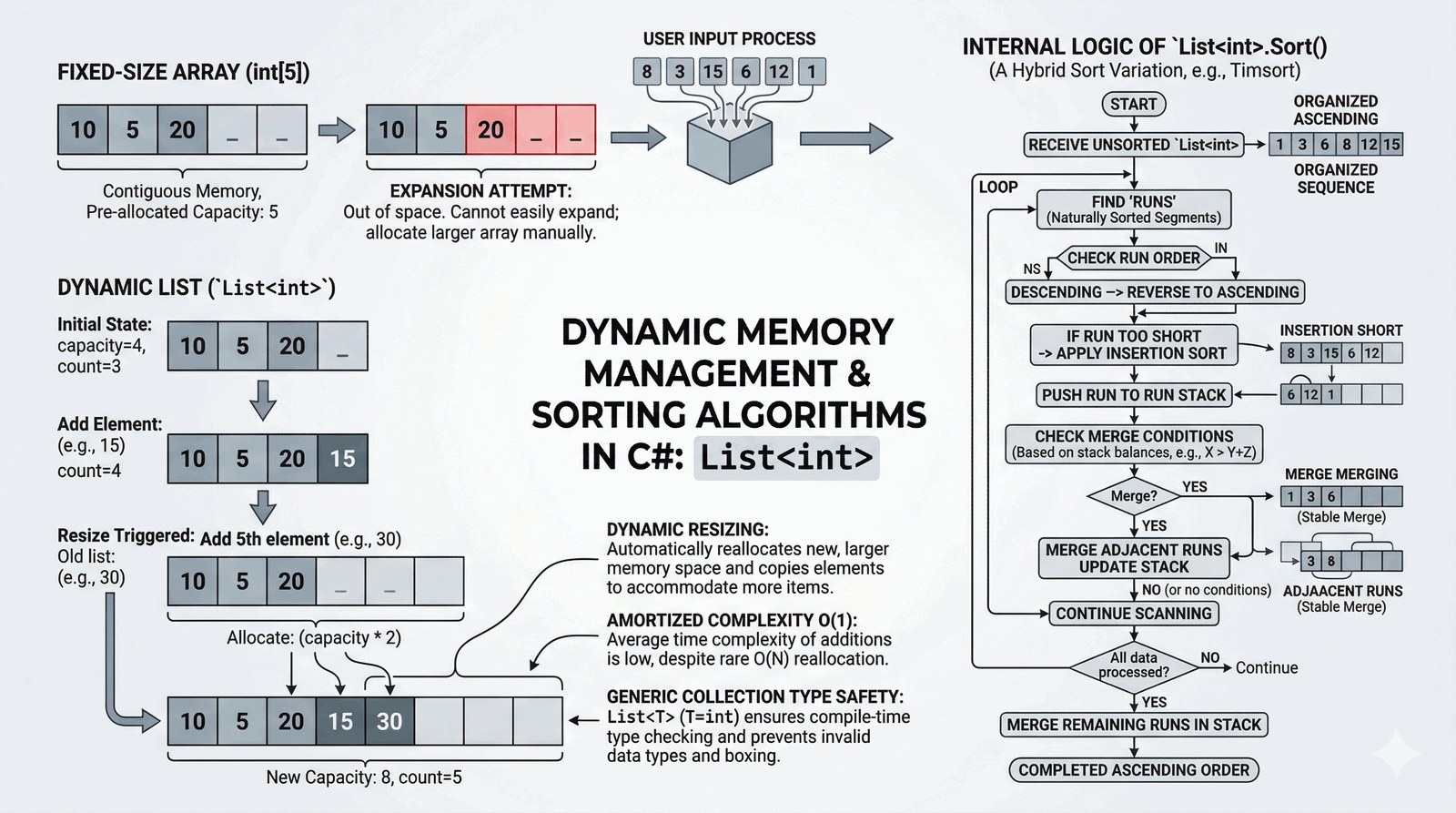
Celem zadania jest opanowanie pracy z generyczną kolekcją List<T> do przechowywania zbiorów danych o nieznanym z góry rozmiarze. Student pozna różnice między statycznymi tablicami a dynamicznymi listami oraz nauczy się wykorzystywać wbudowane algorytmy sortujące platformy .NET.
Jako deweloper w firmie logistycznej otrzymałeś zlecenie na przygotowanie modułu porządkującego numery przesyłek przychodzących do magazynu w trybie ciągłym. Proces wprowadzania danych jest dynamiczny, ponieważ operator nie wie dokładnie, ile paczek zostanie dostarczonych w danej partii, dlatego aplikacja musi reagować na wpisanie wartości kończącej sesję. Każda wprowadzona liczba całkowita reprezentuje unikalny identyfikator paczki, który musi trafić do bezpiecznej, dynamicznie rozszerzalnej kolekcji danych. Po zasygnalizowaniu przez użytkownika końca pracy, system powinien błyskawicznie uporządkować zgromadzone ID w porządku rosnącym, korzystając z wydajnych metod sortowania. Wynik końcowy musi być zaprezentowany jako jednolity ciąg znaków, co umożliwi szybką weryfikację kompletności dostawy przez personel magazynowy. Tego typu rozwiązanie eliminuje ryzyko błędów ludzkich przy ręcznym segregowaniu dokumentacji. Implementacja ta pokazuje, jak nowoczesne kolekcje C# upraszczają zarządzanie dynamicznymi zbiorami obiektów.
Kolekcja List<int> jest generyczną strukturą danych, która dynamicznie zarządza rozmiarem wewnętrznej tablicy w miarę dodawania nowych elementów. W przeciwieństwie do tablic, lista automatycznie alokuje więcej pamięci, gdy jej aktualna pojemność (Capacity) zostanie przekroczona. Metoda Add() wstawia nowy element na koniec kolekcji, co zazwyczaj odbywa się w czasie stałym O(1), chyba że następuje zmiana rozmiaru. Pętla while (true) pozwala na nieskończone zbieranie danych, aż do napotkania warunku przerwania break wywołanego wartością zero. Mechanizm generyczności (<int>) zapewnia bezpieczeństwo typów na etapie kompilacji, eliminując potrzebę rzutowania obiektów. Metoda Sort() wykorzystuje zoptymalizowany algorytm IntroSort, który łączy cechy QuickSort, HeapSort i InsertionSort. Sortowanie odbywa się w miejscu (in-place), co oznacza, że oryginalna kolejność elementów w liście zostaje trwale zmieniona. Zastosowanie metody statycznej string.Join() pozwala na elegancką konkatenację wszystkich elementów kolekcji w jeden ciąg znaków z separatorem. Lista jest typem referencyjnym, a jej właściwość Count dynamicznie zwraca aktualną liczbę przechowywanych obiektów. Wartość 0 pełni rolę "sentinel value", sygnalizując koniec strumienia danych wejściowych bez konieczności deklarowania rozmiaru na starcie. Runtime .NET zarządza rozszerzaniem listy poprzez tworzenie nowej tablicy o podwojonym rozmiarze i kopiowanie do niej istniejących danych. Wykorzystanie przestrzeni nazw System.Collections.Generic jest niezbędne do poprawnej kompilacji struktur generycznych. Porządkowanie danych jest operacją o złożoności O(n log n), co jest standardem dla efektywnych algorytmów sortowania w bibliotekach systemowych. Lista pozwala na łatwy dostęp do elementów poprzez indeksator, podobnie jak w tradycyjnych tablicach C#. Implementacja ta demonstruje elastyczność nowoczesnych kolekcji w porównaniu do sztywnych struktur o stałym rozmiarze. Program promuje modularne podejście do przetwarzania danych: od wejścia, przez transformację, aż po sformatowane wyjście.
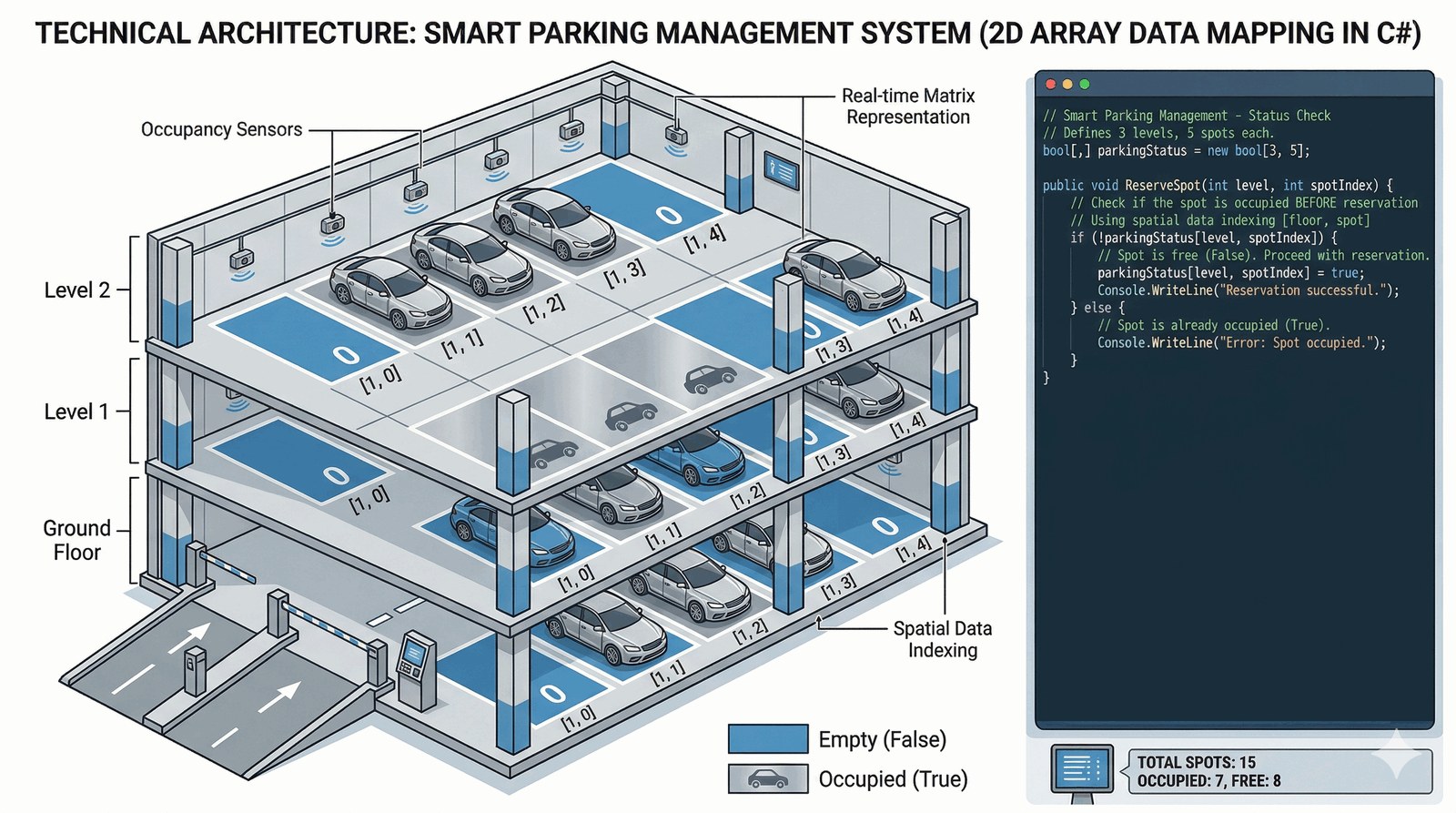
Celem zadania jest praktyczne zastosowanie tablic dwuwymiarowych do modelowania i symulacji przestrzennych układów danych w formacie siatki. Student nauczy się operować na indeksach macierzy oraz zarządzać stanem logicznym elementów rozmieszczonych w strukturze wielowarstwowej.
Zarząd nowoczesnego biurowca w centrum miasta zlecił Ci opracowanie prototypu systemu do zarządzania inteligentnym parkingiem wielopoziomowym. Obiekt posiada trzy piętra, a na każdym z nich znajduje się dokładnie pięć wyznaczonych miejsc postojowych, co wymaga stworzenia precyzyjnej mapy cyfrowej w pamięci aplikacji. Twoim zadaniem jest zaimplementowanie interfejsu, który w przejrzysty sposób wizualizuje aktualne obłożenie parkingu, odróżniając miejsca wolne od zajętych za pomocą czytelnych symboli graficznych. Użytkownik systemu – np. pracownik ochrony – musi mieć możliwość dokonania rezerwacji konkretnego miejsca poprzez wskazanie numeru piętra oraz numeru stanowiska. Algorytm powinien rygorystycznie weryfikować dostępność wybranej przestrzeni i blokować próby podwójnej rezerwacji tego samego miejsca. Po pomyślnym zatwierdzeniu operacji, stan parkingu musi zostać zaktualizowany, a użytkownik poinformowany o sukcesie rezerwacji. System ten ma na celu optymalizację wykorzystania dostępnej przestrzeni parkingowej oraz redukcję czasu potrzebnego na znalezienie wolnego miejsca.
Tablice dwuwymiarowe w C#, deklarowane jako bool[,], są strukturami prostokątnymi, gdzie każdy element ma przypisane współrzędne (wiersz, kolumna). Deklaracja new bool[3, 5] tworzy spójną macierz w pamięci, inicjalizując wszystkie pola wartością domyślną false. Dostęp do konkretnego miejsca postojowego wymaga podania dwóch indeksów wewnątrz operatora [,], co precyzyjnie adresuje komórkę pamięci. Wizualizacja stanu parkingu opiera się na zagnieżdżonych pętlach for, gdzie zewnętrzna pętla iteruje po piętrach, a wewnętrzna po miejscach. Operator warunkowy trójargumentowy ? : służy do skrótowej zamiany wartości logicznej na czytelny symbol graficzny (np. [X] lub [ ]). Walidacja zajętości miejsca odbywa się poprzez instrukcję if, która sprawdza aktualny stan logiczny pod wskazanym adresem macierzy. Zmiana stanu miejsca na zajęte (true) jest operacją atomową, natychmiastowo aktualizującą model danych w pamięci RAM. Metoda int.Parse() konwertuje wejście tekstowe na indeksy liczbowe, co pozwala na mapowanie decyzji użytkownika na strukturę danych. Indeksowanie macierzy zaczyna się od zera, więc piętra są adresowane jako 0, 1 i 2, co wymaga uwagi przy projektowaniu interfejsu. Tablice wielowymiarowe różnią się od tablic nieregularnych tym, że każdy wiersz musi mieć tę samą liczbę kolumn. Pamięć dla macierzy jest alokowana jako jeden ciągły blok, co sprzyja wydajności odczytu dzięki mechanizmom cache'owania procesora. Użycie typu bool jest optymalne dla reprezentacji stanów binarnych (wolne/zajęte), zajmując minimalną ilość miejsca w strukturze. Program demonstruje technikę "mappingu" rzeczywistej przestrzeni fizycznej na cyfrową reprezentację macierzową. Próba dostępu do indeksu spoza zakresu (np. piętro 5) spowoduje błąd czasu wykonania, co podkreśla rolę walidacji zakresów. Implementacja ta uczy myślenia o danych w kategoriach współrzędnych i siatek, co jest fundamentem grafiki i systemów GIS. Struktura ta pozwala na łatwy rozbudowę o dodatkowe wymiary, np. czas rezerwacji lub typ pojazdu, poprzez zmianę typu bazowego tablicy.
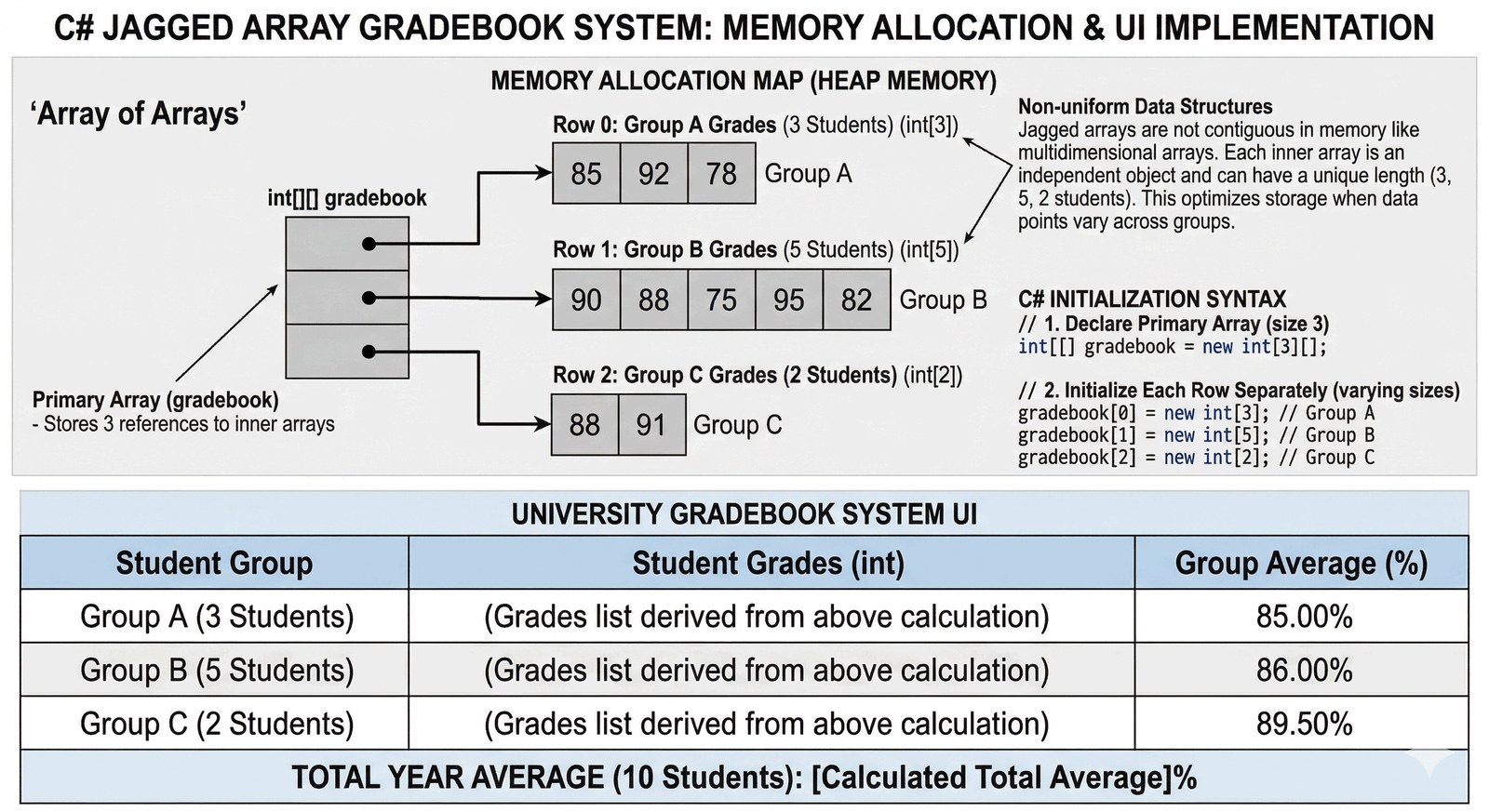
Celem zadania jest zrozumienie architektury tablic nieregularnych (jagged arrays) i ich praktyczne wykorzystanie w sytuacjach, gdy struktura danych nie jest jednorodna. Student zdobędzie umiejętność poprawnej inicjalizacji "tablicy tablic" oraz precyzyjnego dostępu do elementów w wierszach o różnej długości.
Systemy edukacyjne często borykają się z problemem różnorodności grup zajęciowych, gdzie każda z nich liczy inną liczbę studentów, co wyklucza użycie standardowych tablic prostokątnych. Twoim zadaniem jest stworzenie cyfrowego dziennika ocen dla wydziału uczelni, który obsłuży trzy grupy o zróżnicowanej liczebności w sposób optymalny pod kątem wykorzystania pamięci. Aplikacja musi umożliwiać nauczycielowi wprowadzenie ocen dla każdego studenta z osobna, zachowując przy tym ścisły podział na grupy A, B i C. Po zebraniu wszystkich danych, system powinien przeprowadzić analizę statystyczną, wyliczając średnią arytmetyczną dla każdej grupy oraz ogólny wskaźnik sukcesu dla całego roku akademickiego. Kluczowym wyzwaniem jest poprawna alokacja każdego "wiersza" tablicy nieregularnej, co symuluje rzeczywiste warunki dynamicznego przydziału zasobów w systemach bazodanowych. Rozwiązanie to pozwala na elastyczne zarządzanie danymi bez marnowania miejsca na puste komórki, co jest kluczowe w profesjonalnych systemach ERP. Takie podejście uczy programistę dbałości o wydajność i strukturę przechowywanych informacji.
Tablice nieregularne (jagged arrays), definiowane jako int[][], to w rzeczywistości "tablice tablic", gdzie każdy wiersz może mieć inny rozmiar. Główna tablica przechowuje referencje do innych tablic, co pozwala na bardzo elastyczne zarządzanie pamięcią w sytuacjach o zmiennej liczebności grup. Inicjalizacja new int[3][] tworzy strukturę bazową, ale każdy z jej elementów (wierszy) musi zostać zainicjalizowany oddzielnie słowem new. Taka architektura zapobiega marnowaniu pamięci na puste komórki, co miałoby miejsce w przypadku sztywnej macierzy prostokątnej. Dostęp do oceny konkretnego studenta odbywa się za pomocą podwójnego operatora indeksowego, np. dziennik[1][4]. Pierwszy indeks wybiera referencję do konkretnej tablicy (grupy), a drugi wskazuje element wewnątrz tej konkretnej instancji. Właściwość Length wywołana na dziennik[0] zwraca liczbę studentów tylko w pierwszej grupie, co jest kluczowe dla obliczeń statystycznych. Iteracja po takim dzienniku wymaga użycia zagnieżdżonych pętli, gdzie wewnętrzna pętla dopasowuje swój zakres do długości bieżącego wiersza. Tablice nieregularne oferują lepszą wydajność w pewnych scenariuszach JVM/CLR dzięki zoptymalizowanemu sprawdzaniu granic (bounds check). Inicjalizacja klamrowa (initializer list) pozwala na szybkie zdefiniowanie startowej struktury ocen bez wielokrotnego wywoływania konstruktorów. Typ int zapewnia precyzyjną reprezentację ocen bez ryzyka błędów zmiennoprzecinkowych przy ich wprowadzaniu. Obliczanie średniej arytmetycznej wymaga rzutowania sumy na typ double przed dzieleniem, aby uniknąć obcięcia części ułamkowej (dzielenie całkowite). Każdy "wiersz" tablicy nieregularnej jest osobnym obiektem na stercie, co daje dużą swobodę w ich niezależnej wymianie lub sortowaniu. System ten doskonale modeluje relacje typu "jeden do wielu" o zmiennym natężeniu, typowe dla struktur bazodanowych. Zrozumienie różnicy między int[,] a int[][] jest fundamentalnym sprawdzianem wiedzy o zarządzaniu pamięcią w .NET. Program stanowi solidną podstawę do budowy zaawansowanych systemów zarządzania rekordami o niejednorodnej charakterystyce.
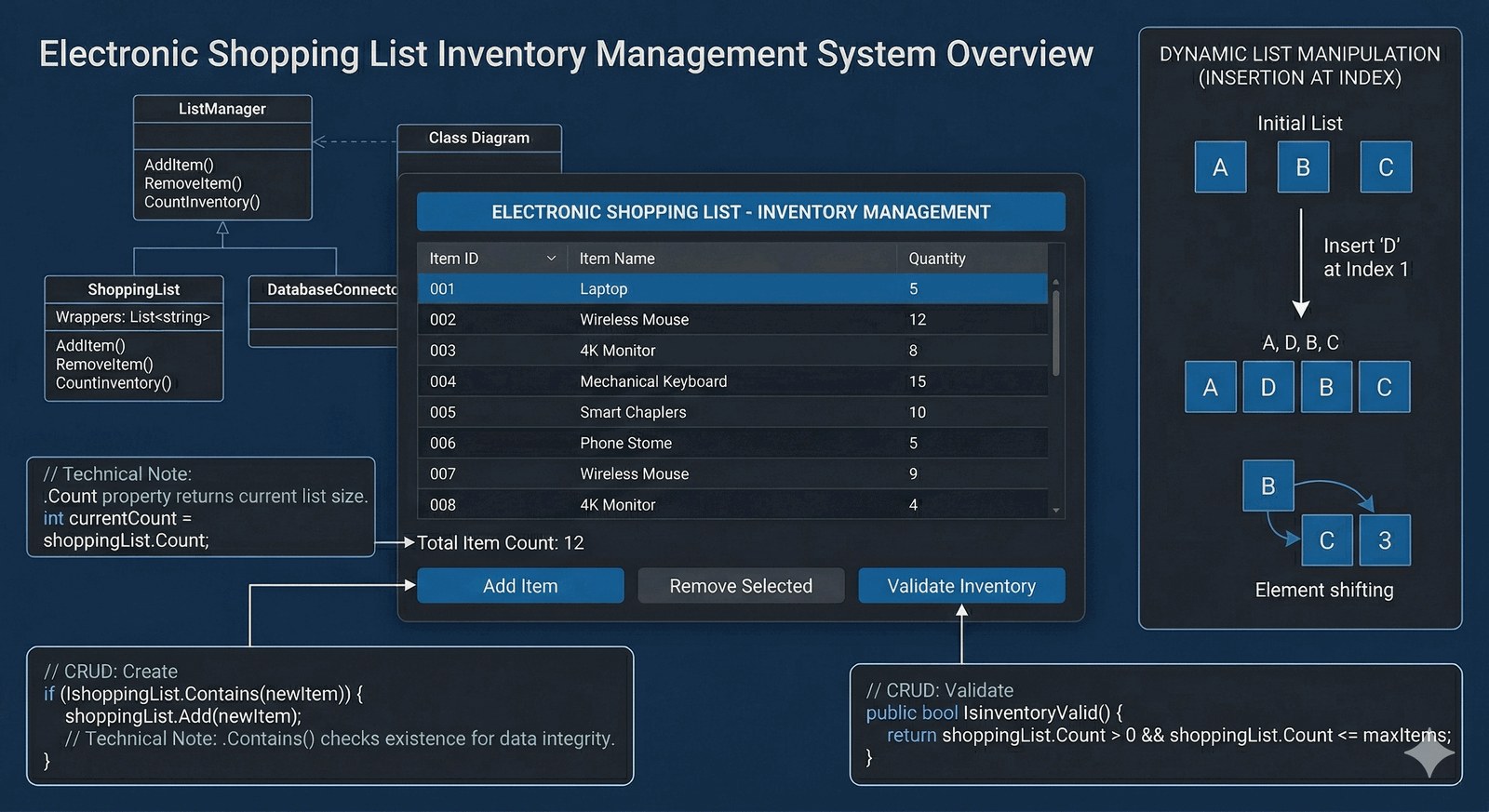
Celem zadania jest praktyczne wykorzystanie kolekcji List<string> do budowy interaktywnego systemu zarządzania dynamicznymi elementami tekstowymi. Student nauczy się realizować pełny cykl życia danych w kolekcji, obejmujący dodawanie, usuwanie oraz przeglądanie zawartości zbioru w czasie rzeczywistym.
W dobie cyfryzacji codziennych obowiązków, Twoja firma postanowiła stworzyć lekką aplikację mobilną wspierającą użytkowników w planowaniu zakupów domowych. Głównym wymaganiem biznesowym jest stworzenie stabilnego silnika listy zakupów, który pozwala na swobodne dodawanie nowych pozycji oraz usuwanie tych, które zostały już nabyte lub są zbędne. Program musi być wyposażony w intuicyjne menu tekstowe, które prowadzi użytkownika przez dostępne operacje i chroni go przed błędami, takimi jak próba usunięcia nieistniejącego produktu. Każda zmiana na liście powinna być natychmiastowo potwierdzana komunikatem informującym o aktualnym stanie zapasów oraz łącznej liczbie przedmiotów oczekujących na zakup. Dzięki zastosowaniu list generycznych, aplikacja może obsługiwać dowolną liczbę produktów bez ryzyka przepełnienia bufora, co zapewnia płynność działania nawet przy bardzo długich zestawieniach. System ten jest idealnym przykładem implementacji wzorca CRUD w prostym interfejsie konsolowym. Ostatecznym celem jest dostarczenie narzędzia, które oszczędza czas użytkownika i zapobiega dublowaniu zakupów.
Wykorzystana kolekcja List<string> implementuje interfejs IList, oferując bogaty zestaw metod do manipulacji elementami tekstowymi. Metoda Add() dołącza nowy łańcuch znaków na koniec listy, automatycznie rozszerzając jej pojemność w razie potrzeby. Mechanizm wyszukiwania Contains() przeszukuje całą listę liniowo (O(n)), sprawdzając czy dany ciąg znaków już w niej występuje. Usuwanie elementów może odbywać się na dwa sposoby: poprzez wartość za pomocą Remove() lub przez pozycję za pomocą RemoveAt(). Usunięcie elementu ze środka listy powoduje przesunięcie wszystkich kolejnych obiektów o jedną pozycję w lewo w celu zachowania ciągłości. Właściwość Count zwraca aktualną liczbę elementów, co jest niezbędne do walidacji poprawności indeksów przy operacjach usuwania. Stringi w C# są obiektami niemutowalnymi, więc lista przechowuje referencje do tych obiektów ulokowanych w pamięci sterty. Interaktywne menu oparte na switch lub if pozwala na mapowanie komend użytkownika na konkretne metody kolekcji. Walidacja zakresu przed wywołaniem RemoveAt() zapobiega zgłoszeniu wyjątku ArgumentOutOfRangeException. Lista generyczna eliminuje ryzyko błędów typu (boxing/unboxing), które występowały w starszych strukturach takich jak ArrayList. Możliwość czyszczenia całej listy za pomocą metody Clear() pozwala na szybki restart procesu planowania zakupów. Iteracja foreach pozwala na bezpieczne wyświetlenie wszystkich produktów bez obawy o błędy indeksowania poza zakresem. Pamięć dla listy jest zwalniana przez Garbage Collector dopiero wtedy, gdy żadna zmienna w programie nie odwołuje się już do tej instancji. Zastosowanie listy zamiast tablicy znaków pozwala na operowanie na całych słowach jako niepodzielnych jednostkach logicznych. Implementacja wzorca CRUD (Create, Read, Update, Delete) w tym zadaniu jest idealnym wstępem do programowania aplikacji bazodanowych. Całość kodu skupia się na zapewnieniu płynności interakcji użytkownika z dynamicznie zmieniającym się zbiorem danych.
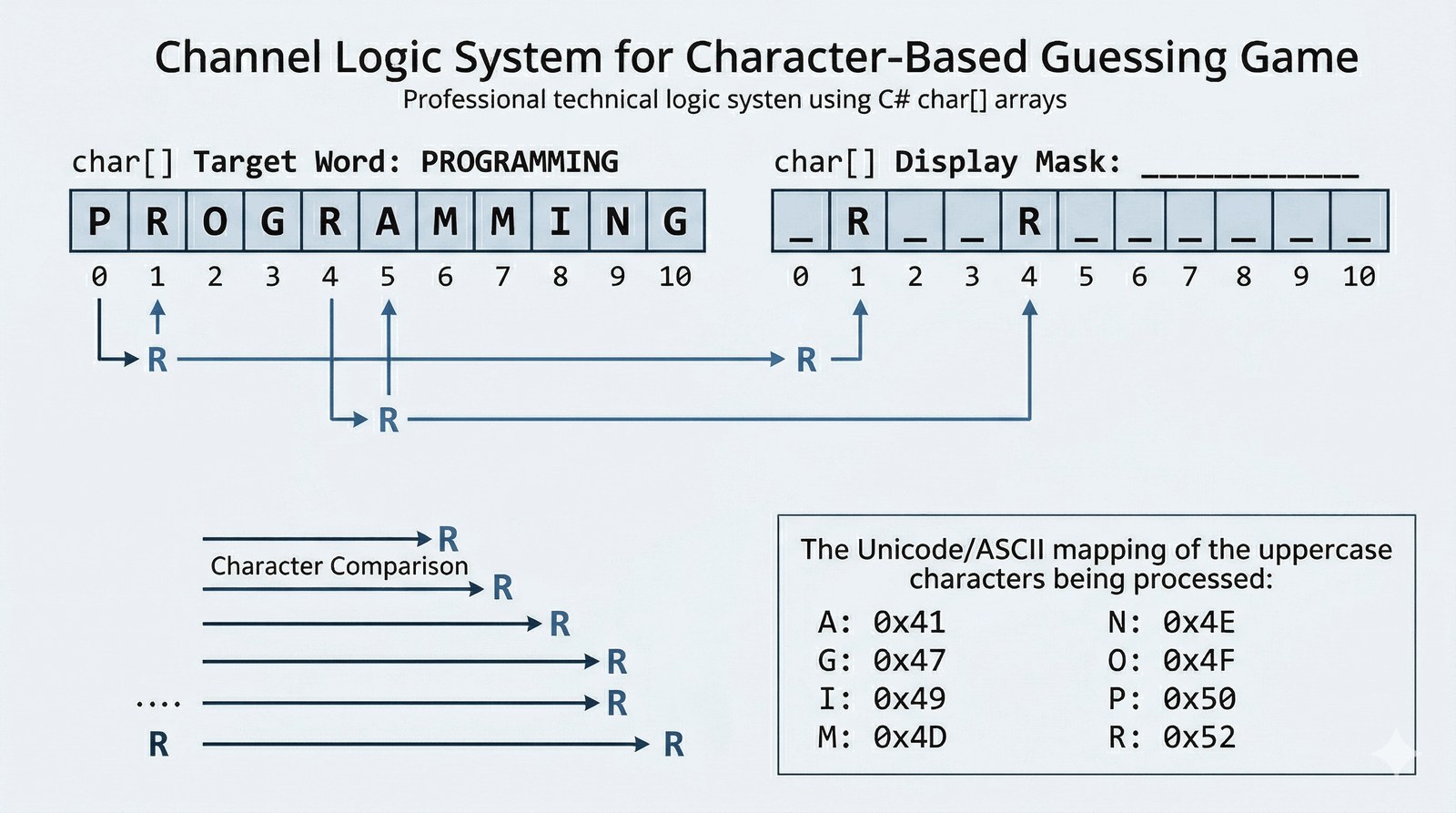
Celem zadania jest pogłębienie wiedzy na temat tablic znaków (char[]) oraz technik manipulacji pojedynczymi elementami tekstowymi w algorytmach logicznych. Student przećwiczy synchronizację dwóch struktur danych – jawnego wzorca oraz ukrytej maski – w celu realizacji interaktywnego procesu odgadywania.
Branża rozrywkowa często poszukuje szybkich i angażujących gier logicznych, które można zaimplementować na różnych platformach sprzętowych. Twoim zadaniem jest opracowanie silnika do klasycznej gry w odgadywanie haseł, znanej jako "Wisielec", skupiając się na poprawnej obsłudze stanów gry. Aplikacja przechowuje tajne słowo w pamięci, a przed użytkownikiem wyświetla jedynie jego zaszyfrowaną postać składającą się z podkreślników, co buduje napięcie i angażuje do myślenia. Gracz wprowadza litery, a system musi błyskawicznie przeszukać strukturę hasła i odsłonić trafione znaki w odpowiednich miejscach tablicy maskującej. Mechanizm ten wymaga precyzyjnego porównywania typów znakowych oraz dbania o to, by wielkość liter nie wpływała negatywnie na poprawność weryfikacji. Rozgrywka toczy się w pętli do momentu całkowitego odkrycia tajemnicy, co jest doskonałym ćwiczeniem z zakresu kontroli przepływu danych i walidacji wejścia. Tego typu moduł może stać się częścią większego portalu edukacyjnego lub aplikacji mobilnej do nauki języków obcych.
Kluczowym elementem algorytmu jest synchronizacja tablicy char[] slowo (hasło) z tablicą char[] maska (postęp gracza). Tablica maska jest inicjalizowana w pętli znakiem podkreślenia '_', co tworzy wizualną barierę przed odkryciem hasła. Metoda Console.ReadLine() zwraca string, z którego pobieramy tylko pierwszy znak za pomocą indeksatora [0]. Normalizacja wielkości liter za pomocą char.ToUpper() pozwala na poprawne porównywanie znaków niezależnie od klawisza Shift. Algorytm przeszukiwania iteruje przez całą tablicę slowo, porównując wprowadzoną literę z każdym znakiem hasła. W przypadku trafienia, odpowiedni indeks w tablicy maska jest aktualizowany znakiem z hasła, co odsłania literę użytkownikowi. Wykorzystanie konstruktora new string(maska) pozwala na błyskawiczną konwersję tablicy znaków na obiekt typu string gotowy do wyświetlenia. Walidacja wejścia za pomocą string.IsNullOrEmpty() chroni program przed awarią przy naciśnięciu samego klawisza Enter. Instrukcja continue w pętli pozwala na pominięcie błędnych iteracji i natychmiastowy powrót do etapu pobierania znaku. Gra toczy się zazwyczaj w pętli while lub do-while, aż do momentu, gdy tablica maska przestanie zawierać znaki podkreślenia. Tablice typu char są typami wartościowymi przechowywanymi w ciągłym bloku, co zapewnia wysoką wydajność porównań bitowych. Porównywanie znaków odbywa się na poziomie ich kodów numerycznych Unicode (np. 'A' to 65), co jest operacją natywną dla procesora. Mechanizm maskowania jest klasycznym przykładem oddzielenia danych ukrytych od warstwy prezentacji widocznej dla użytkownika. Rozwiązanie to uczy operowania na pojedynczych bajtach informacji wewnątrz większych struktur tekstowych. Implementacja może zostać rozbudowana o licznik prób, co wymagałoby dodania dodatkowej zmiennej całkowitej typu int. Zrozumienie manipulacji na poziomie char jest niezbędne przy pisaniu parserów, kompilatorów i systemów kryptograficznych.
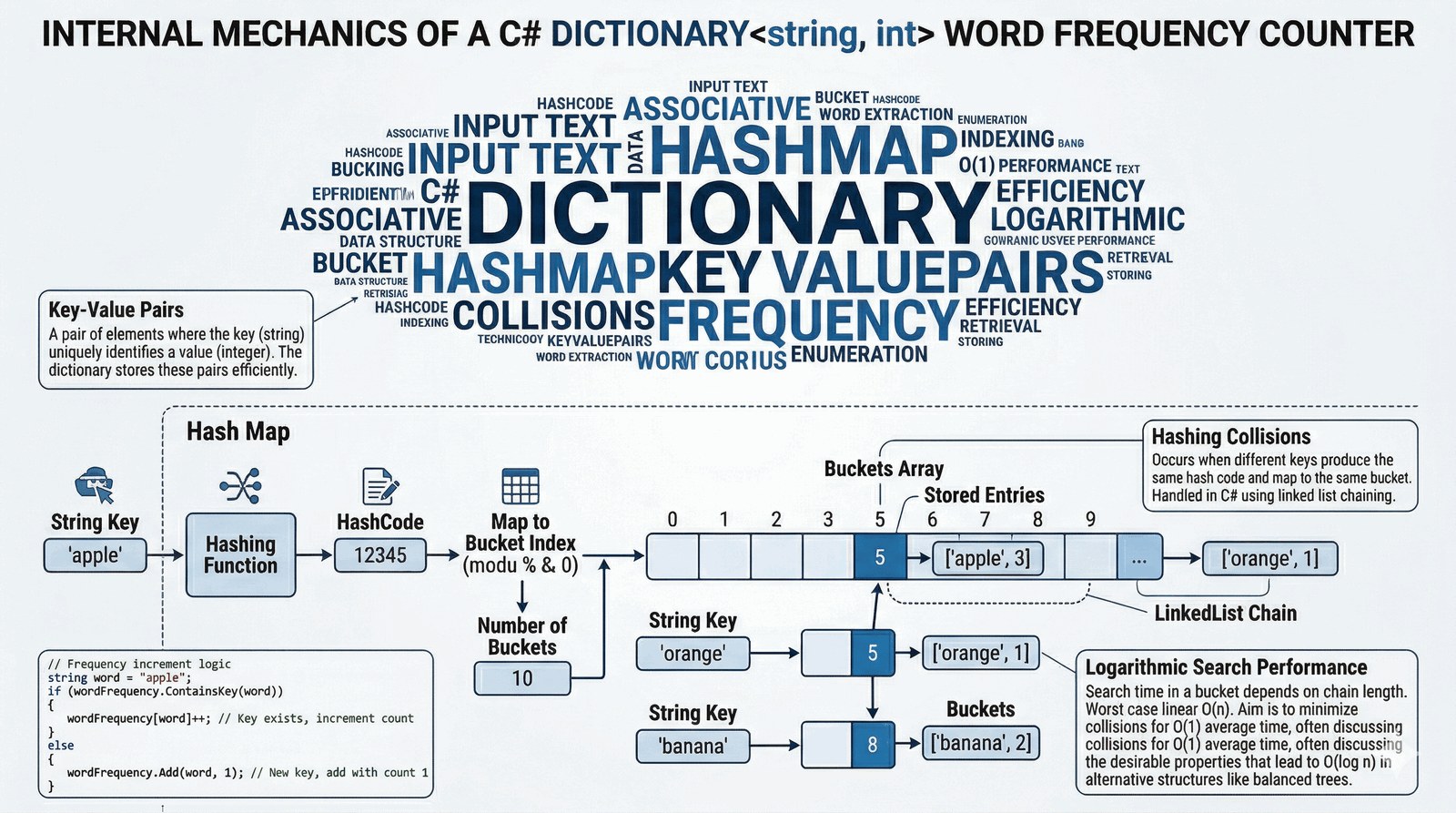
Celem zadania jest wprowadzenie studenta w świat asocjacyjnych struktur danych poprzez implementację słownika Dictionary<TKey, TValue>. Ćwiczenie koncentruje się na efektywnym zliczaniu unikalnych wystąpień elementów oraz optymalizacji wyszukiwania informacji w dużych zbiorach danych tekstowych.
W nowoczesnym marketingu internetowym analiza treści (Content Analysis) jest kluczowa dla optymalizacji tekstów pod kątem wyszukiwarek i czytelności. Twoja agencja SEO potrzebuje narzędzia, które w kilka sekund dostarczy szczegółowy raport na temat gęstości słów kluczowych w nadesłanych artykułach. Zadaniem programu jest pobranie od użytkownika dowolnego fragmentu tekstu, podzielenie go na poszczególne wyrazy i dokładne zliczenie częstotliwości występowania każdego z nich. Wykorzystując strukturę słownikową, aplikacja musi sprawnie mapować słowa na ich liczebność, dbając o unikalność kluczy i poprawną aktualizację liczników. Wynikiem końcowym jest zestawienie statystyczne, które pokazuje, jakie słowa dominują w tekście, co pozwala na szybką korektę redakcyjną lub optymalizację pod kątem algorytmów Google. Implementacja ta uczy, jak radzić sobie z nieustrukturyzowanymi danymi tekstowymi i zamieniać je w wartościową wiedzę biznesową. To doskonały przykład wykorzystania struktur typu klucz-wartość do rozwiązywania problemów z zakresu analityki danych.
Struktura Dictionary<string, int> reprezentuje tablicę mieszającą (hash table), przechowującą unikalne pary klucz-wartość. Metoda Split() dzieli wejściowy ciąg znaków na tablicę słów, wykorzystując spację jako separator i usuwając puste wpisy. Przetwarzanie słów odbywa się w pętli foreach, gdzie każde słowo jest sprawdzane pod kątem obecności w słowniku metodą ContainsKey(). Jeśli klucz istnieje, inkrementujemy powiązaną z nim wartość liczbową (licznik[s]++), co aktualizuje częstotliwość występowania. W przypadku nowego słowa, metoda Add() wstawia nową parę do struktury, inicjując licznik wartością 1. Wyszukiwanie w słowniku odbywa się w czasie amortyzowanym stałym O(1), co czyni go niezwykle wydajnym dla dużych tekstów. Podczas iteracji po słowniku otrzymujemy obiekty typu KeyValuePair<string, int>, które zawierają właściwości Key oraz Value. Klucze w słowniku muszą być unikalne; próba dodania istniejącego klucza metodą Add() spowodowałaby zgłoszenie wyjątku. Słownik generyczny zapewnia bezpieczeństwo typów, eliminując błędy rzutowania przy dostępie do danych statystycznych. Kolekcja ta automatycznie zarządza procesem hashowania kluczy tekstowych w celu optymalnego rozmieszczenia ich w pamięci. Wykorzystanie słowa kluczowego var w pętli upraszcza składnię przy pracy ze złożonymi typami generycznymi par klucz-wartość. Pamięć dla słownika jest alokowana na stercie, a jego rozmiar rośnie dynamicznie wraz z liczbą unikalnych słów w tekście. Mechanizm ten jest fundamentem dla algorytmów analizy częstotliwościowej i budowania indeksów wyszukiwarek internetowych. Należy pamiętać, że porównywanie kluczy w słowniku domyślnie uwzględnia wielkość liter (Case Sensitive), chyba że podano inny IEqualityComparer. Implementacja ta pokazuje przewagę struktur asocjacyjnych nad zwykłymi listami w zadaniach zliczania i kategoryzacji. Program uczy, jak zamienić nieustrukturyzowany strumień tekstu w uporządkowany model danych statystycznych gotowy do raportowania.
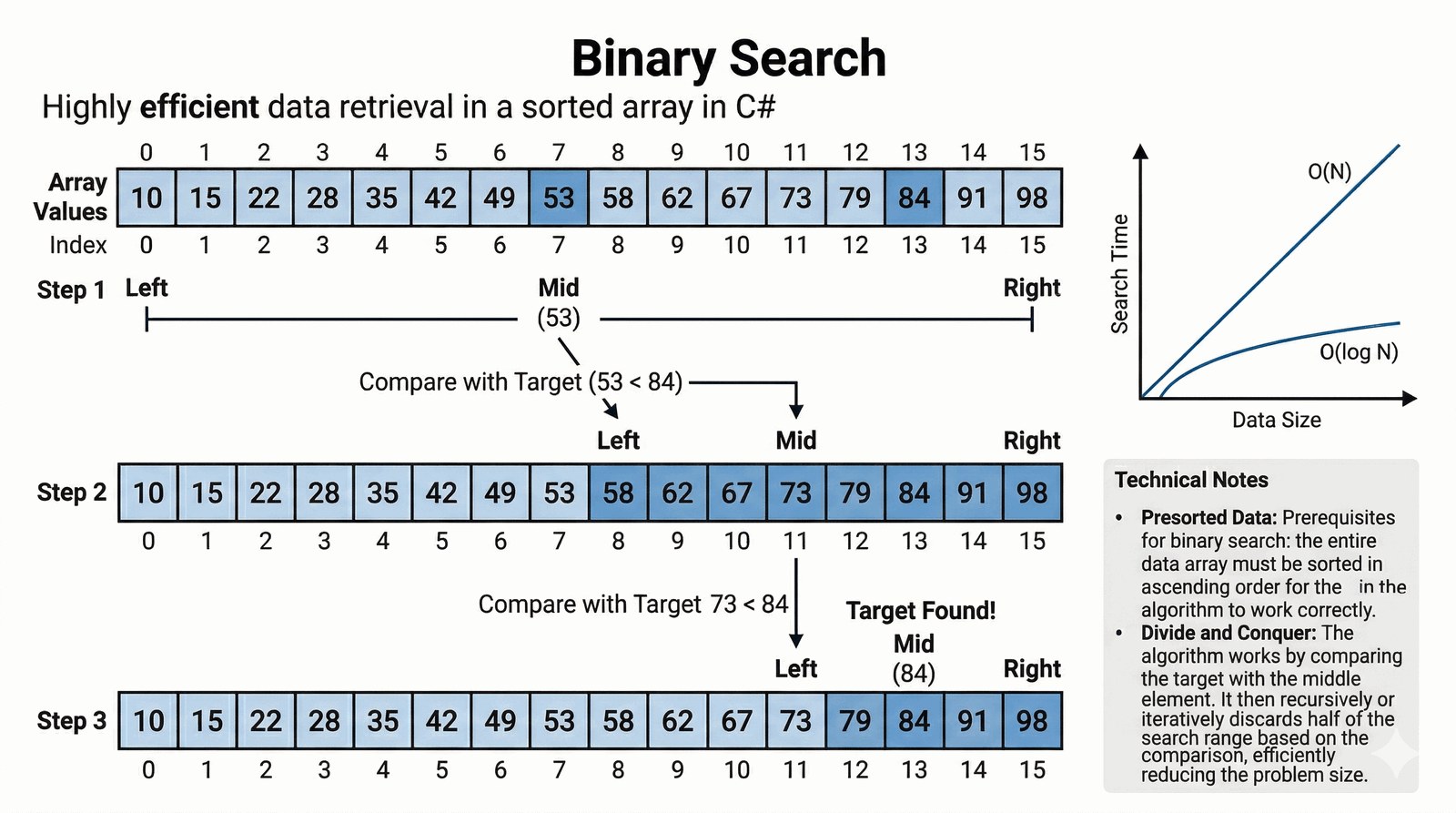
Celem zadania jest implementacja oraz analiza wydajności algorytmu wyszukiwania binarnego (Binary Search) w posortowanych zbiorach danych. Student nauczy się stosować strategię "dziel i zwyciężaj", co pozwoli na drastyczne skrócenie czasu wyszukiwania w porównaniu do metod liniowych.
Szybkość dostępu do informacji jest fundamentem sukcesu w branży e-commerce, zwłaszcza gdy baza produktów liczy miliony rekordów. Jako inżynier systemowy musisz zaimplementować mechanizm błyskawicznego odnajdywania indeksów towarów w posortowanym spisie inwentarzowym. Tradycyjne przeszukiwanie element po elemencie jest zbyt wolne dla systemów czasu rzeczywistego, dlatego zdecydowałeś się na wdrożenie algorytmu wyszukiwania binarnego. Program musi inteligentnie dzielić zakres poszukiwań na połowę przy każdej iteracji, co pozwala na odnalezienie dowolnego elementu w rekordowo krótkim czasie, nawet w gigantycznych bazach danych. System wymaga jednak, aby dane wejściowe były uprzednio posortowane, co uczy studenta dbałości o jakość struktur przed przystąpieniem do ich procesowania. Rozwiązanie to nie tylko optymalizuje zużycie procesora, ale również znacząco poprawia komfort pracy użytkownika końcowego poprzez eliminację opóźnień. Takie algorytmy są sercem nowoczesnych systemów plików i silników baz danych, z którymi będziesz pracować w przyszłości.
Algorytm wyszukiwania binarnego (Binary Search) operuje na posortowanych tablicach, drastycznie redukując liczbę porównań do logarytmicznej skali O(log n). Metoda przyjmuje dwa parametry: tablicę liczb int[] tablica oraz poszukiwaną wartość int szukana. Logika opiera się na dwóch wskaźnikach (lewy i prawy), które definiują aktualnie przeszukiwany zakres indeksów. W każdej iteracji pętli while wyliczany jest indeks środkowy (srodek), dzieląc zbiór danych na dwie równe części. Obliczenie srodek = lewy + (prawy - lewy) / 2 zapobiega potencjalnemu przepełnieniu zakresu typu int przy bardzo dużych tablicach. Jeśli wartość pod indeksem środkowym jest równa szukanej, algorytm natychmiast zwraca pozycję i kończy działanie. Gdy szukana jest większa, przesuwamy lewą granicę na srodek + 1, efektywnie odrzucając całą lewą połowę zbioru. W przeciwnym razie aktualizujemy prawą granicę, co zawęża poszukiwania do mniejszych wartości w tablicy. Pętla wykonuje się dopóki lewy <= prawy; jeśli warunek przestanie być spełniony, zwracana jest wartość -1 oznaczająca brak elementu. Wydajność tego podejścia jest imponująca – dla miliona elementów potrzeba maksymalnie 20 porównań, by znaleźć dowolną liczbę. Tablica wejściowa musi być uprzednio posortowana, co jest warunkiem koniecznym dla poprawnego działania logiki dzielenia zakresów. Zastosowanie wyszukiwania binarnego jest kluczowe w systemach o wysokiej responsywności i ograniczonych zasobach procesora. Implementacja ta uczy stosowania strategii "dziel i zwyciężaj", która jest fundamentem informatyki teoretycznej i stosowanej. Warto zauważyć, że algorytm ten jest wbudowany w .NET jako metoda Array.BinarySearch(), ale samodzielna implementacja uczy rozumienia procesów niskopoziomowych. Zmienne lokalne wewnątrz funkcji są przechowywane na stosie, co gwarantuje błyskawiczny dostęp do wskaźników granic. Program demonstruje, jak matematyczna optymalizacja algorytmu przekłada się na realne oszczędności czasu wykonania w systemach produkcyjnych.
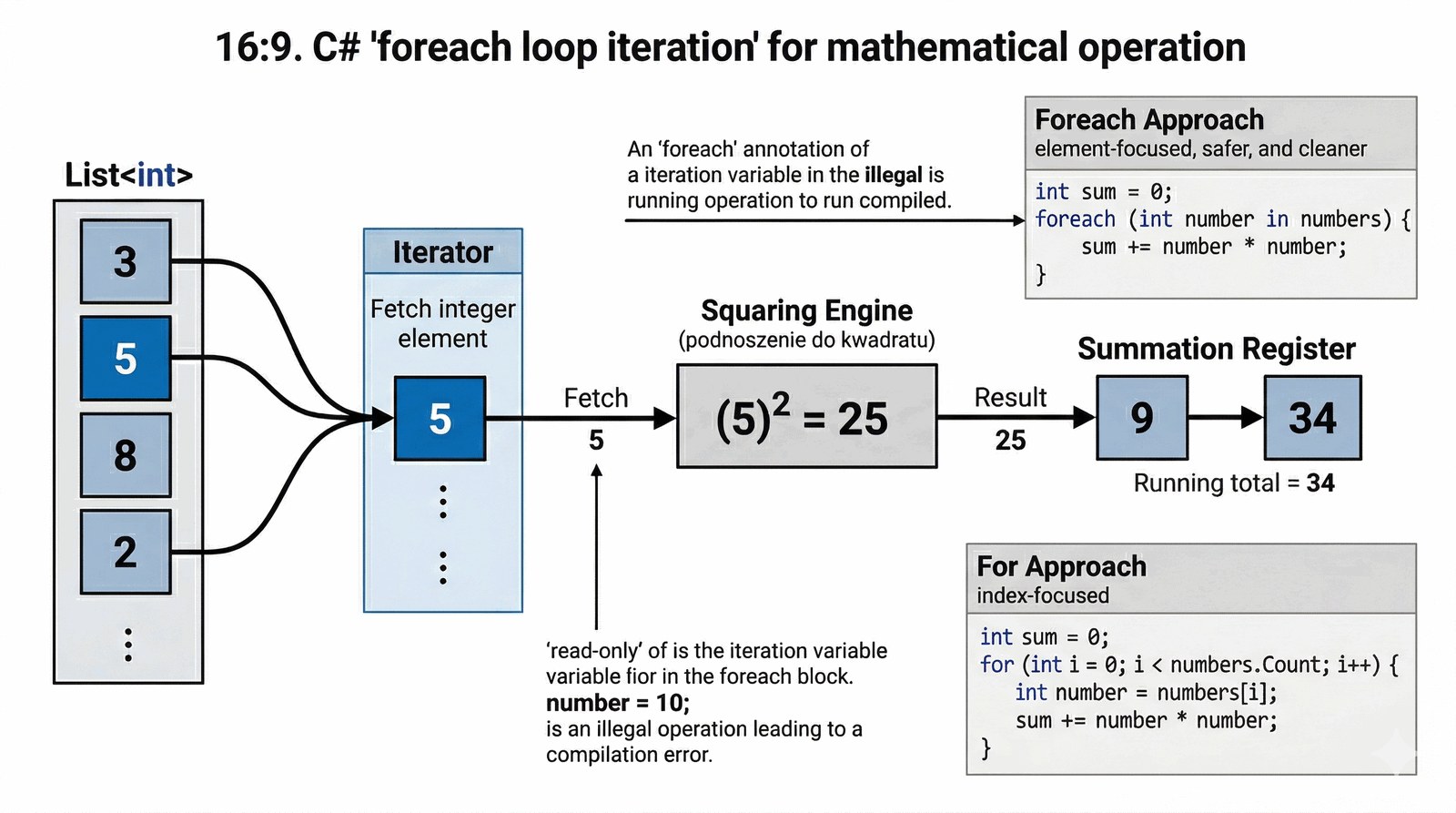
Celem zadania jest opanowanie nowoczesnej składni pętli foreach jako bezpieczniejszej i bardziej czytelnej alternatywy dla tradycyjnych pętli indeksowanych. Student nauczy się procesować elementy kolekcji bez ryzyka wystąpienia błędów przekroczenia zakresu tablicy.
W analityce finansowej często zachodzi potrzeba przeprowadzania skomplikowanych obliczeń na dużych zbiorach danych transakcyjnych, gdzie liczy się czystość i niezawodność kodu. Twoim zadaniem jest przygotowanie modułu obliczeniowego, który przetworzy listę wartości portfela inwestycyjnego, wyliczając sumę kwadratów poszczególnych kwot w celu analizy odchyleń statystycznych. Zamiast operować na surowych indeksach, wykorzystasz pętlę foreach, która gwarantuje przejrzystość logiki i minimalizuje ryzyko błędów typu "off-by-one" przy przetwarzaniu dynamicznych kolekcji. Program powinien sekwencyjnie przechodzić przez wszystkie elementy, prezentować proces obliczeń dla każdego kroku i na końcu dostarczyć precyzyjny wynik zbiorczy. Takie podejście promuje standardy "Clean Code", które są wymagane w profesjonalnych zespołach programistycznych pracujących nad krytycznymi systemami bankowymi. Implementacja ta uświadamia, że wybór odpowiedniego mechanizmu iteracji ma bezpośredni wpływ na łatwość utrzymania i testowania oprogramowania w długofalowej perspektywie.
Pętla foreach jest dedykowaną konstrukcją do bezpiecznej iteracji po kolekcjach implementujących interfejs IEnumerable. Wewnętrznie pętla ta korzysta z mechanizmu enumeratora, który sekwencyjnie dostarcza kolejne elementy bez ujawniania indeksów. Zastosowanie typu long dla zmiennej sumaKwadratow chroni program przed przepełnieniem (overflow) przy sumowaniu dużych wartości. Obliczanie kwadratu liczby odbywa się poprzez mnożenie elementu przez samego siebie, co jest wydajniejsze niż wywoływanie Math.Pow(). Pętla foreach gwarantuje, że nie wystąpi błąd IndexOutOfRangeException, ponieważ mechanizm automatycznie zatrzymuje się na końcu kolekcji. Jednym z ograniczeń foreach jest brak możliwości modyfikacji elementów kolekcji w trakcie iteracji, co zapewnia integralność danych. Kod wewnątrz pętli wyświetla wynik pośredni dla każdego elementu, prezentując proces obliczeń w czasie rzeczywistym. Interpolacja stringów $"{x}^2 = {kwadrat}" pozwala na czytelną prezentację operacji matematycznych w konsoli. Lista List<int> została zainicjalizowana za pomocą "collection initializer", co upraszcza składnię tworzenia zbioru testowego. Wykorzystanie rzutowania jawnego (long)x * x zapewnia, że operacja mnożenia zostanie wykonana na 64-bitowych rejestrach procesora. Pętla ta promuje styl deklaratywny, gdzie programista skupia się na tym "co" zrobić z każdym elementem, a nie "jak" nawigować po indeksach. W profesjonalnym kodzie C# (Clean Code) foreach jest zawsze preferowany nad for, o ile dostęp do indeksu nie jest niezbędny. Enumerator używany przez pętlę jest obiektem lekkim, a jego cykl życia jest automatycznie zarządzany przez runtime .NET. Implementacja ta uświadamia znaczenie doboru odpowiednich typów numerycznych do skali wykonywanych obliczeń matematycznych. Program demonstruje połączenie nowoczesnej składni kolekcji z klasycznymi operacjami arytmetycznymi o wysokiej precyzji. Całość rozwiązania skupia się na czytelności, bezpieczeństwie i niezawodności przetwarzania serii danych liczbowych.
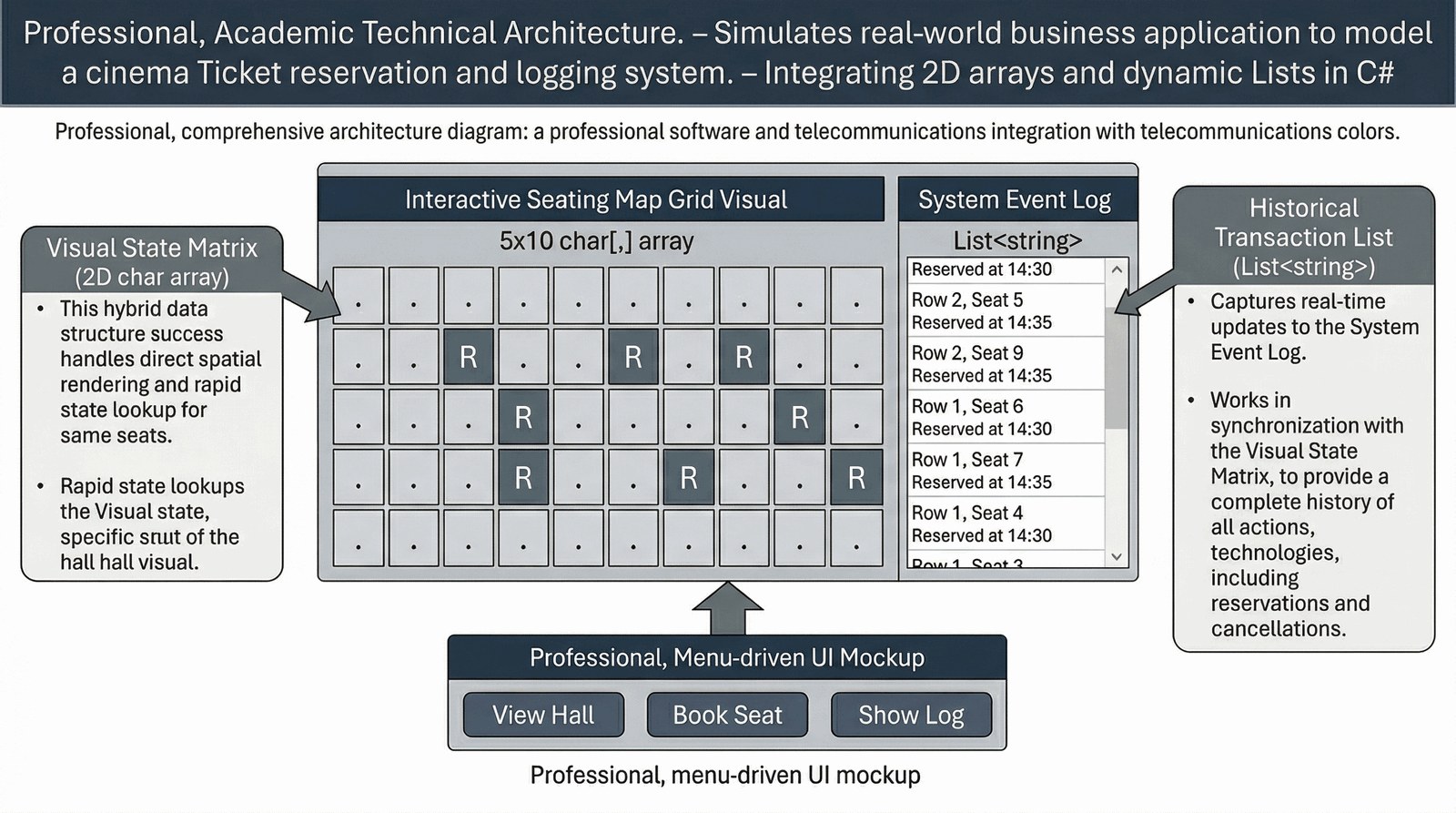
Celem zadania jest integracja różnorodnych struktur danych, takich jak tablice wielowymiarowe i listy generyczne, w ramach jednej, zaawansowanej aplikacji biznesowej. Student nauczy się koordynować przepływ informacji między wizualną reprezentacją stanu systemu a historycznym dziennikiem zdarzeń.
Nowo powstająca sieć kin potrzebuje kompleksowego systemu do zarządzania rezerwacjami miejsc w salach projekcyjnych, który będzie łączył funkcje podglądu fizycznego układu sali z precyzyjnym logowaniem aktywności. Twoim wyzwaniem jest stworzenie hybrydowej aplikacji, która wykorzystuje macierz znaków do reprezentowania mapy foteli oraz dynamiczną listę do przechowywania chronologicznej historii wszystkich transakcji. System musi umożliwiać pracownikom obsługi klienta szybkie sprawdzenie dostępności konkretnych rzędów, dokonywanie rezerwacji w czasie rzeczywistym oraz generowanie raportów z przebiegu sprzedaży. Każda udana operacja powinna nie tylko zmieniać stan wizualny sali, ale również tworzyć szczegółowy wpis w dzienniku zdarzeń, zawierający dokładny czas i współrzędne zarezerwowanego miejsca. Takie podejście symuluje architekturę rzeczywistych systemów enterprise, gdzie dane operacyjne muszą być spójne z audytowymi logami systemowymi. Projekt ten stanowi zwieńczenie modułu o kolekcjach, pokazując jak synergia różnych struktur danych pozwala na budowę profesjonalnego i odpornego na błędy oprogramowania.
System wykorzystuje tablicę dwuwymiarową char[,] sala o stałych wymiarach do reprezentowania fizycznej struktury miejsc (5 rzędów, 10 kolumn). Dodatkowo, generyczna lista List<string> historia służy jako dynamiczny dziennik zdarzeń, przechowujący nieograniczoną liczbę wpisów tekstowych. Inicjalizacja sali odbywa się za pomocą zagnieżdżonych pętli for, ustawiając domyślny stan wszystkich miejsc jako wolne (znak kropki). Logika rezerwacji sprawdza wartość w macierzy pod wskazanymi współrzędnymi; jeśli miejsce jest wolne, zmienia znak na 'R'. Po każdej udanej rezerwacji, metoda Add() dopisuje do listy sformatowany komunikat zawierający szczegóły operacji i czas. Wykorzystanie macierzy pozwala na błyskawiczny podgląd wizualny sali, co symuluje interfejs graficzny dla pracownika obsługi. Lista logów (historia) demonstruje separację danych bieżących (stan sali) od danych historycznych (rejestr akcji). Wykorzystanie foreach do wyświetlania logów pozwala na płynne przeglądanie całej historii operacji bez martwienia się o jej rozmiar. Program demonstruje współdziałanie struktur o stałym rozmiarze (macierz) z elastycznymi kolekcjami dynamicznymi (lista). Walidacja dostępności miejsca sala[rzad, miejsce] == '.' zapobiega błędom nadpisywania istniejących rezerwacji przez innych użytkowników. Takie podejście architektoniczne jest typowe dla systemów klasy Enterprise, gdzie stan systemu musi być poparty audytowalnym dziennikiem zmian. Zastosowanie typu char dla sali jest oszczędne pod kątem pamięci, pozwalając na szybką prezentację tekstową mapy miejsc. System uczy studenta koordynacji zmian w wielu strukturach danych jednocześnie w odpowiedzi na pojedynczą akcję użytkownika. Implementacja może zostać łatwo rozbudowana o zapis do pliku, co uczyniłoby system trwałym (persistent) pomiędzy uruchomieniami. Zrozumienie synergii między różnymi kolekcjami jest kluczową umiejętnością przy projektowaniu złożonych silników biznesowych. Całość projektu stanowi kompleksowe podsumowanie wiedzy o strukturach danych, pętlach i logice warunkowej w języku C#.