Poniższy zestaw zadań nie ogranicza się jedynie do składni, ale kładzie nacisk na architektoniczne zrozumienie sposobu działania runtime'u .NET. Każde zadanie wymaga przeanalizowania mechanizmów zarządzania pamięcią oraz precyzji operacji na typach danych.
Przewodnik po zagadnieniach
- Wizytówka klienta Auto-Premium - Integracja streamów wejściowych
- Finansowy kalkulator rat - Mechanizmy konwersji i rzutowania
- Diagnostyka systemowa - Reprezentacje bitowe i szesnastkowe
- Zarządzanie księgowością - Precyzja typu Decimal i lokalizacja
- System sterowania kokpitem - Przechwytywanie zdarzeń klawiatury
- Inteligentny dobór oferty - Optymalizacja logiki i operatory skrócone
- Analiza telemetryczna przejazdów - Kontrola pętli i akumulacja
- System weryfikacji danych - Odporna walidacja i mechanizm TryParse
- Wizualizacja wydajności sprzedaży - Algorytmy oparte na pętlach zagnieżdżonych
- Audyt precyzji systemu - Analiza porównawcza arytmetyki binarnej i dziesiętnej
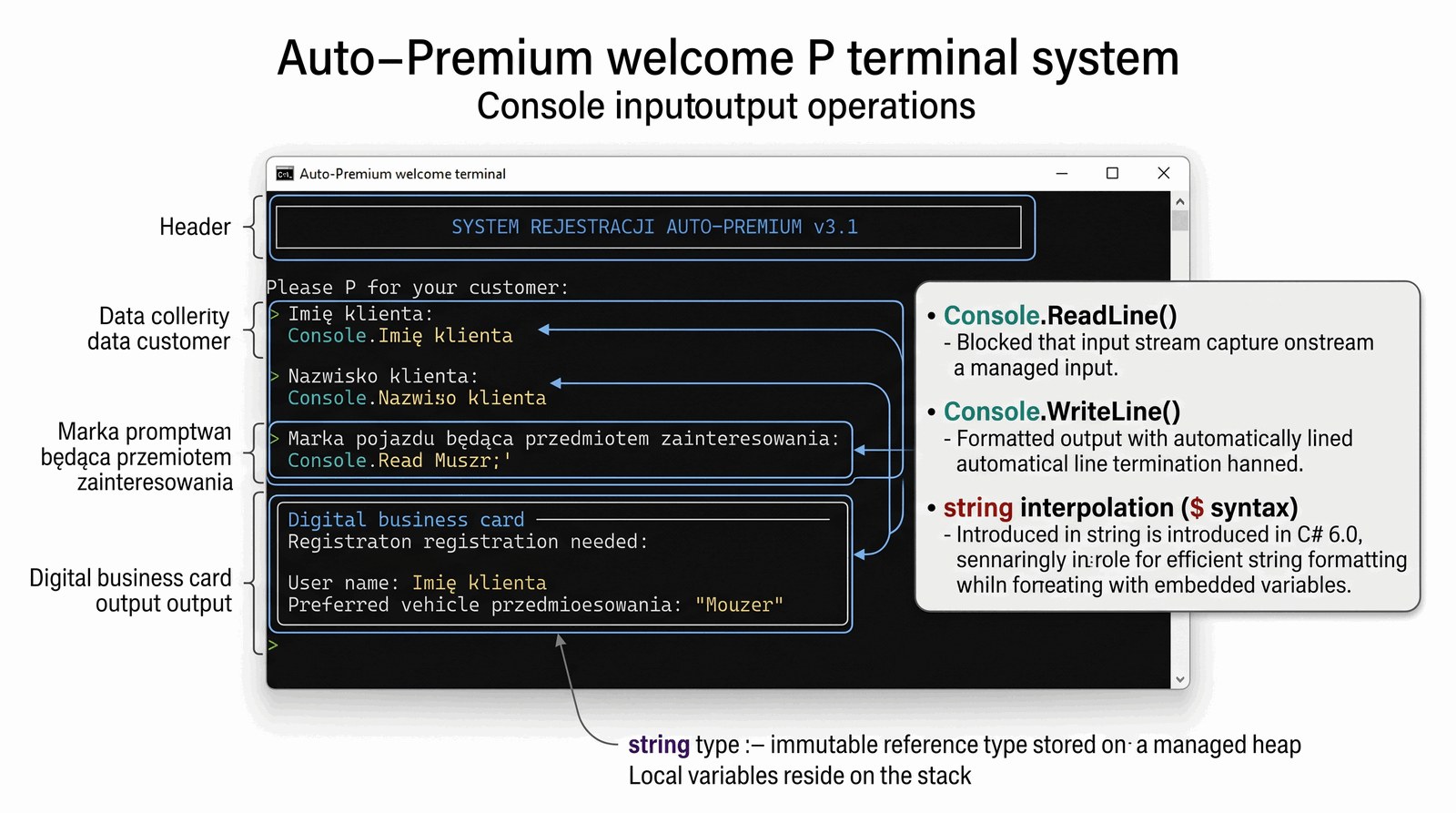
Zrozumienie działania standardowych strumieni wejścia/wyjścia oraz mechanizmu alokacji zmiennych tekstowych w pamięci zarządzanej.
Salon Auto-Premium wprowadza nowoczesny terminal powitalny, który pełni rolę pierwszej linii kontaktu z klientami segmentu luksusowego. Jako programista musisz stworzyć moduł, który w sposób elegancki i bezbłędny zbierze dane osobowe oraz preferencje motoryzacyjne gości. System musi być przygotowany na obsługę różnych zestawów znaków, zachowując przy tym najwyższą czytelność kodu źródłowego. Twoim zadaniem jest zapewnienie, że zebrane informacje zostaną poprawnie sformatowane w formie cyfrowej wizytówki, która zostanie przesłana do systemów CRM salonu. Ten moduł to fundament budowania relacji z klientem, dlatego każda sekunda interakcji musi być dopracowana. Wykorzystasz do tego najnowsze wzorce projektowe w zakresie manipulacji łańcuchami znaków. Program ma za zadanie wyeliminować zbędną biurokrację i przyspieszyć proces obsługi w salonie.
W tym zadaniu fundamentem jest wykorzystanie typu string, który w środowisku .NET pełni rolę referencyjnego typu danych przechowującego sekwencje znaków Unicode. Ważne jest zrozumienie, że obiekty typu string są niemutowalne (immutable), co oznacza, że każda próba ich modyfikacji skutkuje utworzeniem nowej instancji w pamięci sterty (Heap). Metoda Console.ReadLine() jest odpowiedzialna za przechwycenie strumienia wejściowego i zablokowanie wykonania programu do momentu otrzymania znaku nowej linii. Zwracana wartość jest zawsze typu tekstowego, co wymusza na programiście dbałość o poprawne typowanie w dalszych etapach. Zastosowana interpolacja ciągów znaków (znak $ przed cudzysłowem) jest mechanizmem wprowadzonym w C# 6.0, który znacząco zwiększa czytelność kodu w porównaniu do klasycznej konkatenacji. Podczas kompilacji, interpolowany string jest zamieniany na wywołanie metody string.Format, co optymalizuje proces budowania komunikatów. Przestrzeń nazw System dostarcza klasę Console, która jest statycznym interfejsem do interakcji z terminalem systemowym. Należy zwrócić uwagę na różnicę między Write a WriteLine – ta druga metoda automatycznie dodaje ogranicznik linii charakterystyczny dla danego systemu operacyjnego. Prawidłowe nazewnictwo zmiennych (camelCase) sprzyja utrzymaniu standardów czystego kodu (Clean Code). Wykorzystanie znaków ucieczki, takich jak \n, pozwala na precyzyjne sterowanie layoutem tekstowym w konsoli. Pamięć alokowana dla zmiennych lokalnych w metodzie Main znajduje się na stosie (Stack), podczas gdy same dane tekstowe wędrują na stertę. Program demonstruje, jak prosta interakcja z użytkownikiem może być zrealizowana w sposób profesjonalny i wydajny. Każdy element składni służy tutaj budowaniu spójnego i odpornego na błędy interfejsu użytkownika.
namespace AutoPremium.WelcomeTerminal
{
class Program
{
static void Main(string[] args)
{
// Deklaracja zmiennych do przechowywania danych profilowych klienta
string imie, nazwisko, markaDocelowa;
Console.WriteLine("=== SYSTEM REJESTRACJI AUTO-PREMIUM v3.1 ===");
Console.WriteLine("Proszę wprowadzić dane gościa do formularza cyfrowego.\n");
Console.Write("Imię klienta: ");
imie = Console.ReadLine();
Console.Write("Nazwisko klienta: ");
nazwisko = Console.ReadLine();
Console.Write("Marka pojazdu będąca przedmiotem zainteresowania: ");
markaDocelowa = Console.ReadLine();
// Generowanie raportu końcowego z wykorzystaniem interpolacji
string raport = $"\n[REJESTRACJA POMYŚLNA]\nUżytkownik: {imie} {nazwisko}\nPreferowany asortyment: {markaDocelowa}";
Console.WriteLine(raport);
Console.WriteLine(new string('=', 45));
}
}
}
Proszę wprowadzić dane gościa do formularza cyfrowego.
Imię klienta: Małgorzata
Nazwisko klienta: Kwiatkowska
Marka pojazdu będąca przedmiotem zainteresowania: Audi RS6
[REJESTRACJA POMYŚLNA]
Użytkownik: Małgorzata Kwiatkowska
Preferowany asortyment: Audi RS6
=============================================
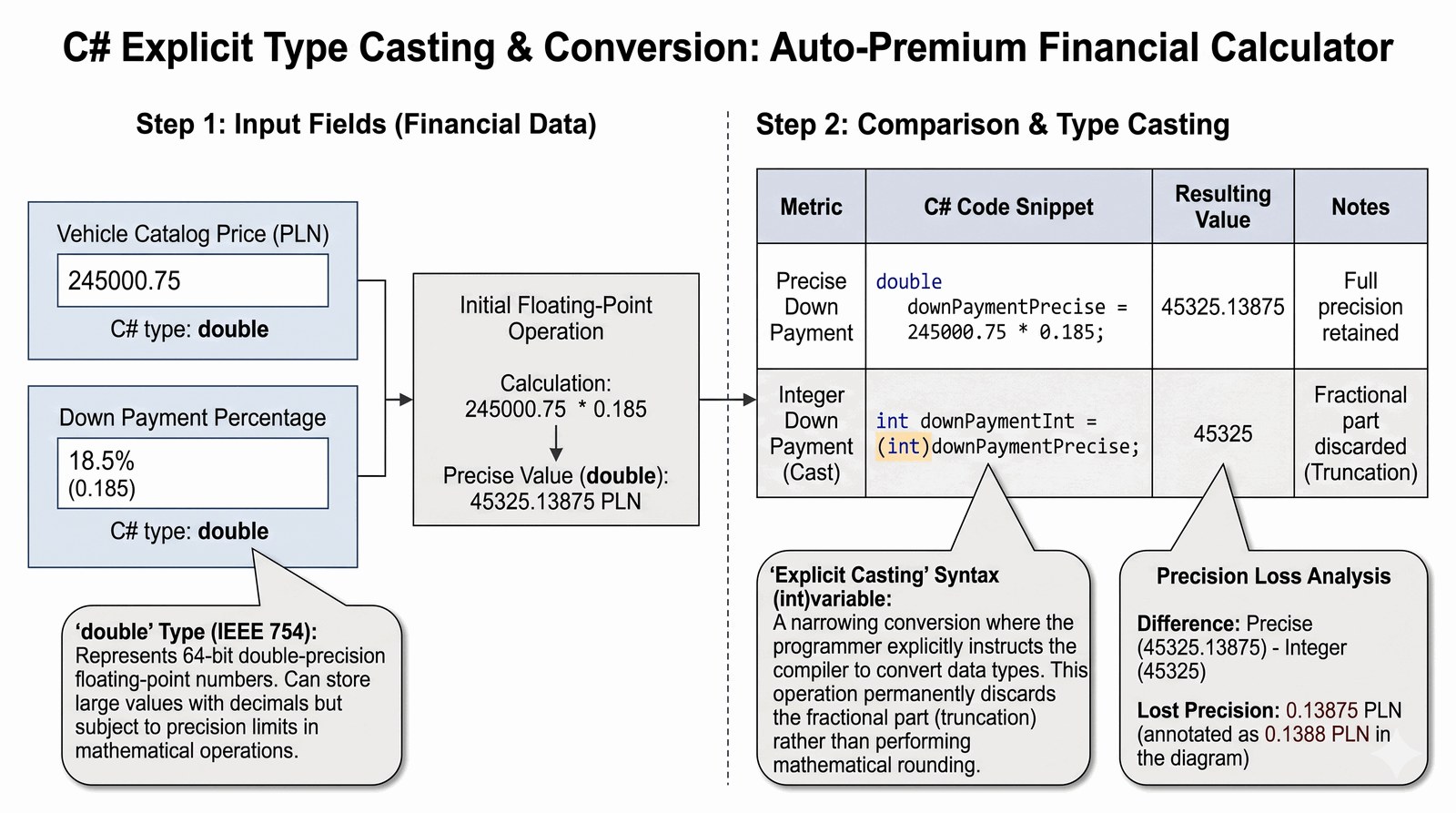
Nauka precyzyjnego operowania na liczbach oraz zrozumienie konsekwencji jawnego rzutowania typów zmiennoprzecinkowych na całkowite.
W dziale finansowym Auto-Premium precyzja jest kluczowa, ale uproszczone raporty okresowe wymagają prezentacji danych w postaci liczb całkowitych. Klient salonu decyduje się na zakup pojazdu o znacznej wartości w systemie ratalnym, co generuje potrzebę obliczenia wpłaty własnej. Twoim zadaniem jest stworzenie algorytmu, który na podstawie ceny katalogowej obliczy dokładną kwotę wpłaty początkowej (np. 18,5%). Wynik ten musi być zaprezentowany w dwóch formach: pełnej (z groszami) oraz zaokrąglonej w dół (same złotówki) dla potrzeb szybkich zestawień statystycznych. Taka operacja symuluje typowe procesy księgowe, gdzie precyzja techniczna spotyka się z wymogami czytelności biznesowej. Program musi uwzględniać, że każda strata groszowa w skali tysięcy transakcji ma znaczenie. Student musi nauczyć się, jak kontrolować te procesy, aby nie dopuścić do błędów finansowych. Scenariusz ten uczy odpowiedzialności za kod operujący na realnych wartościach majątkowych.
W zadaniu wykorzystujemy typ double, który służy do reprezentacji liczb zmiennoprzecinkowych o podwójnej precyzji, zgodnych ze standardem IEEE 754. Ten typ danych alokuje 64 bity w pamięci i pozwala na przechowywanie wartości z dokładnością do 15-17 cyfr znaczących. Napotykamy tu na problem rzutowania jawnego (explicit casting), które polega na wymuszeniu konwersji typu double na int. Taka operacja powoduje bezpowrotną utratę części ułamkowej liczby (następuje ucięcie, a nie matematyczne zaokrąglenie). Składnia (int)zmienna informuje kompilator, że programista jest świadomy ryzyka utraty danych i akceptuje je. Jest to przykład konwersji zwężającej, która musi być wykonana jawnie, aby uniknąć przypadkowych błędów logicznych. Warto zauważyć, że typ int jest 32-bitowym typem całkowitym ze znakiem, co nakłada limity na maksymalną wartość przechowywanej kwoty (ok. 2,1 mld). Zmienne te są przechowywane na stosie (Stack), co zapewnia wysoką wydajność dostępu. Operatory arytmetyczne, takie jak mnożenie (*), działają na typach zmiennoprzecinkowych z zachowaniem precyzji binarnej. Użycie stałych w kodzie, takich jak stawka procentowa, powinno odbywać się poprzez deklaracje zmiennych pomocniczych dla zwiększenia czytelności. Program pokazuje również, jak interpolacja radzi sobie z różnymi typami danych w jednym wyrażeniu. Metoda Console.WriteLine niejawnie wywołuje metodę ToString() na każdym obiekcie, który ma zostać wyświetlony. Zrozumienie domyślnego formatowania liczb w zależności od ustawień regionalnych (Culture) jest istotne przy pracy z polskim złotym. Należy pamiętać, że dla systemów finansowych krytycznych wybiera się zazwyczaj typ decimal, jednak tutaj double służy do demonstracji mechanizmów rzutowania. Każdy krok algorytmu jest zaprojektowany tak, by pokazać przepływ danych od wejścia do przetworzonego wyniku. Wyciąganie wniosków z różnic między wartością dokładną a rzutowaną to kluczowa umiejętność debugowania obliczeń.
class KalkulatorFinansowy
{
static void Main()
{
// Pobieramy cenę katalogową samochodu jako liczbę zmiennoprzecinkową
Console.Write("Podaj cenę katalogową pojazdu (np. 185400,99): ");
double cenaKatalogowa = double.Parse(Console.ReadLine());
// Definiujemy stawkę wpłaty własnej (18,5%)
double stawkaProcentowa = 0.185;
double wplataDokladna = cenaKatalogowa * stawkaProcentowa;
// JAWNE RZUTOWANIE: Konwersja z utratą precyzji dla raportu statystycznego
int wplataZaokraglona = (int)wplataDokladna;
// Prezentacja wyników z analizą różnic
Console.WriteLine("\n--- ANALIZA KOSZTÓW POCZĄTKOWYCH ---");
Console.WriteLine($"1. Kwota wyliczona systemowo: {wplataDokladna} PLN");
Console.WriteLine($"2. Kwota do raportu (całkowita): {wplataZaokraglona} PLN");
// Obliczanie różnicy wynikającej z rzutowania
double roznica = wplataDokladna - wplataZaokraglona;
Console.WriteLine($"Różnica (odcięte grosze): {roznica:F4} PLN");
}
}
--- ANALIZA KOSZTÓW POCZĄTKOWYCH ---
1. Kwota wyliczona systemowo: 45325,13875 PLN
2. Kwota do raportu (całkowita): 45325 PLN
Różnica (odcięte grosze): 0,1388 PLN
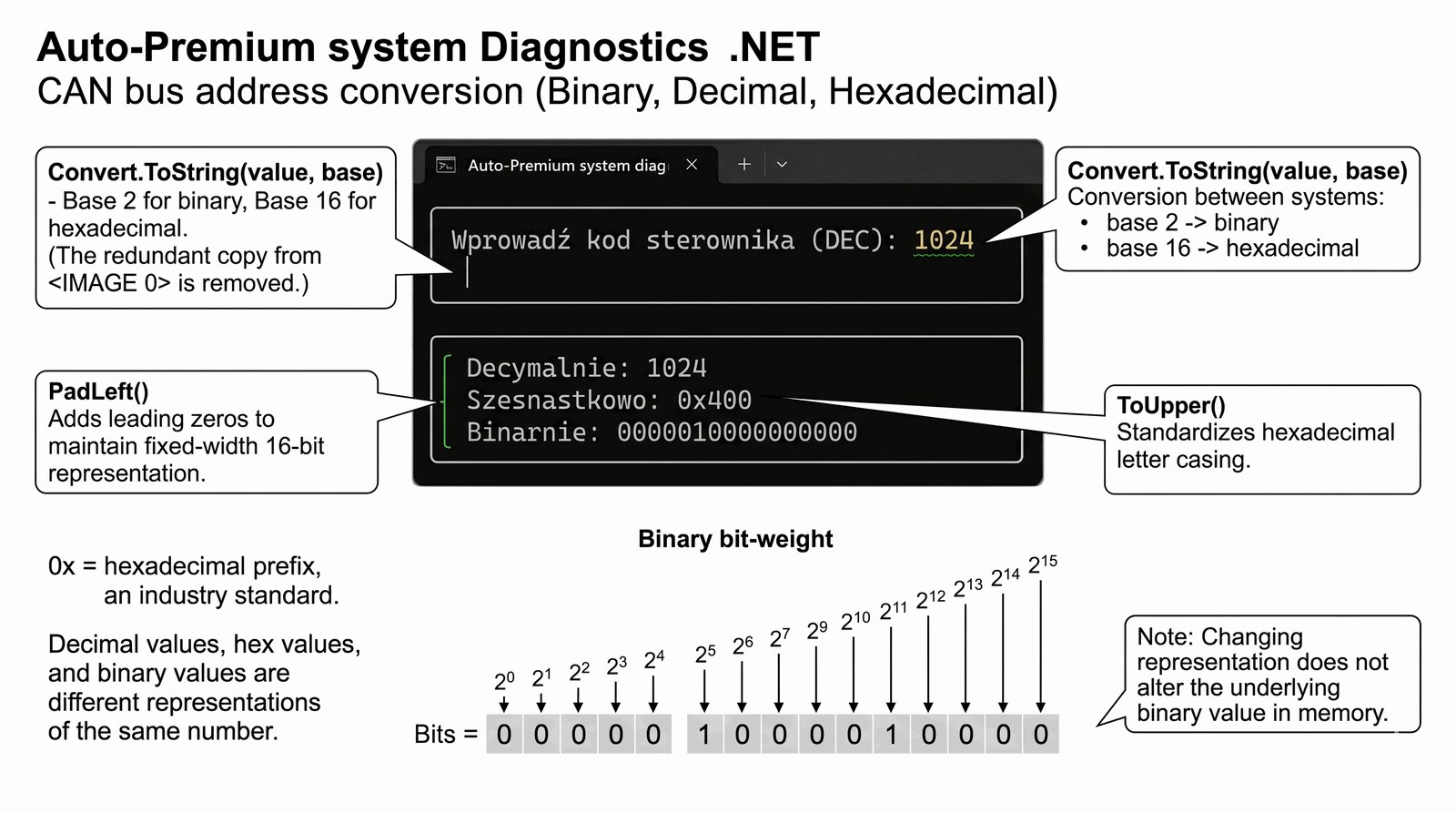
Zrozumienie binarnej natury danych oraz umiejętność prezentacji liczb w różnych systemach pozycyjnych wykorzystywanych w technice.
W warsztacie serwisowym Auto-Premium mechanicy korzystają ze specjalistycznych interfejsów diagnostycznych, które komunikują się bezpośrednio z szyną CAN pojazdu. Każdy podzespół elektroniczny identyfikowany jest przez unikalny, dziesiętny numer seryjny, jednak protokoły komunikacyjne operują wyłącznie na kodzie binarnym i szesnastkowym. Twoim zadaniem jest stworzenie narzędzia wspomagającego pracę inżynierów serwisu, które w czasie rzeczywistym dokona konwersji numerów ID na formaty czytelne dla maszyn. Dzięki temu pracownik będzie mógł szybko zweryfikować adresy modułów na magistrali danych, minimalizując ryzyko pomyłki przy programowaniu sterowników silnika. System musi być intuicyjny, ale i dostarczać surowych danych technicznych niezbędnych do niskopoziomowej analizy błędów. Taka funkcjonalność jest niezbędna przy diagnozowaniu skomplikowanych usterek elektroniki w najnowszych modelach aut. Program stanowi most między ludzką percepcją liczb a binarną logiką komputerów pokładowych. To zadanie wprowadza Cię w świat programowania bliskiego sprzętowi.
W sercu tego zadania leży klasa Convert, która jest częścią biblioteki standardowej .NET i dostarcza statycznych metod do zmiany reprezentacji danych między różnymi typami i systemami. Wykorzystujemy tutaj przeciążoną metodę ToString(int value, int toBase), gdzie drugi parametr określa podstawę systemu liczbowego (w naszym przypadku 2 dla binarnego i 16 dla szesnastkowego). System szesnastkowy (hexadecimal) jest kluczowy w informatyce, gdyż pozwala na zwięzłą reprezentację 8-bitowych bajtów za pomocą dwóch znaków z zakresu 0-F. Konwersja do systemu binarnego (zera i jedynki) pozwala z kolei na wizualizację stanów poszczególnych bitów w pamięci rejestrów procesora. Należy zauważyć, że metoda Convert.ToString zwraca typ string, co pozwala na dalszą obróbkę tekstu, na przykład zmianę liter na wielkie poprzez ToUpper(). Zmiana podstawy systemu nie zmienia wartości liczby w pamięci (tam zawsze jest to binarny int), a jedynie sposób jej prezentacji tekstowej dla człowieka. Metoda int.Parse() służy do zamiany ciągu znaków wprowadzonego z klawiatury na 32-bitową liczbę całkowitą ze znakiem. Obsługa błędów w tym miejscu byłaby wskazana, gdyż podanie tekstu zamiast cyfr spowoduje przerwanie programu (wyjątek FormatException). Zastosowanie prefiksów takich jak "0x" dla liczb szesnastkowych jest standardem w programowaniu (C#, C++, Java), ułatwiającym identyfikację podstawy systemu. Program uczy, jak pracować z różnymi perspektywami tych samych danych, co jest fundamentalne przy debugowaniu transmisji sieciowych czy protokołów sprzętowych. Warto zauważyć, że system binarny w wersji zwracanej przez Convert nie zawiera wiodących zer, chyba że zostaną one dodane ręcznie poprzez metodę PadLeft. Wiedza o systemach pozycyjnych jest niezbędna przy pracy z maskami bitowymi i flagami (Enum), które często pojawiają się w logice sterowników. Precyzyjne formatowanie wyjścia konsolowego z użyciem tabulatorów lub spacji poprawia estetykę i czytelność gotowego narzędzia inżynierskiego.
namespace SerwisDiagnostyczny
{
class KonwerterMagistrali
{
static void Main()
{
Console.WriteLine("=== ANALIZATOR ADRESÓW MAGISTRALI CAN ===");
Console.Write("Wprowadź kod sterownika (DEC): ");
// Odczyt i konwersja wejścia na typ liczbowy
int kodDziesietny = int.Parse(Console.ReadLine());
// Konwersja na system binarny (base 2)
string reprezentacjaBin = Convert.ToString(kodDziesietny, 2).PadLeft(16, '0');
// Konwersja na system szesnastkowy (base 16) z formatowaniem
string reprezentacjaHex = Convert.ToString(kodDziesietny, 16).ToUpper();
// Wynik końcowy dla inżynierów serwisu
Console.WriteLine("\n[STATUS KONWERSJI]");
Console.WriteLine($"Decymalnie: {kodDziesietny}");
Console.WriteLine($"Szesnastkowo: 0x{reprezentacjaHex}");
Console.WriteLine($"Binarnie: {reprezentacjaBin}");
Console.WriteLine(new string('-', 40));
}
}
}
Wprowadź kod sterownika (DEC): 1024
[STATUS KONWERSJI]
Decymalnie: 1024
Szesnastkowo: 0x400
Binarnie: 0000010000000000
----------------------------------------
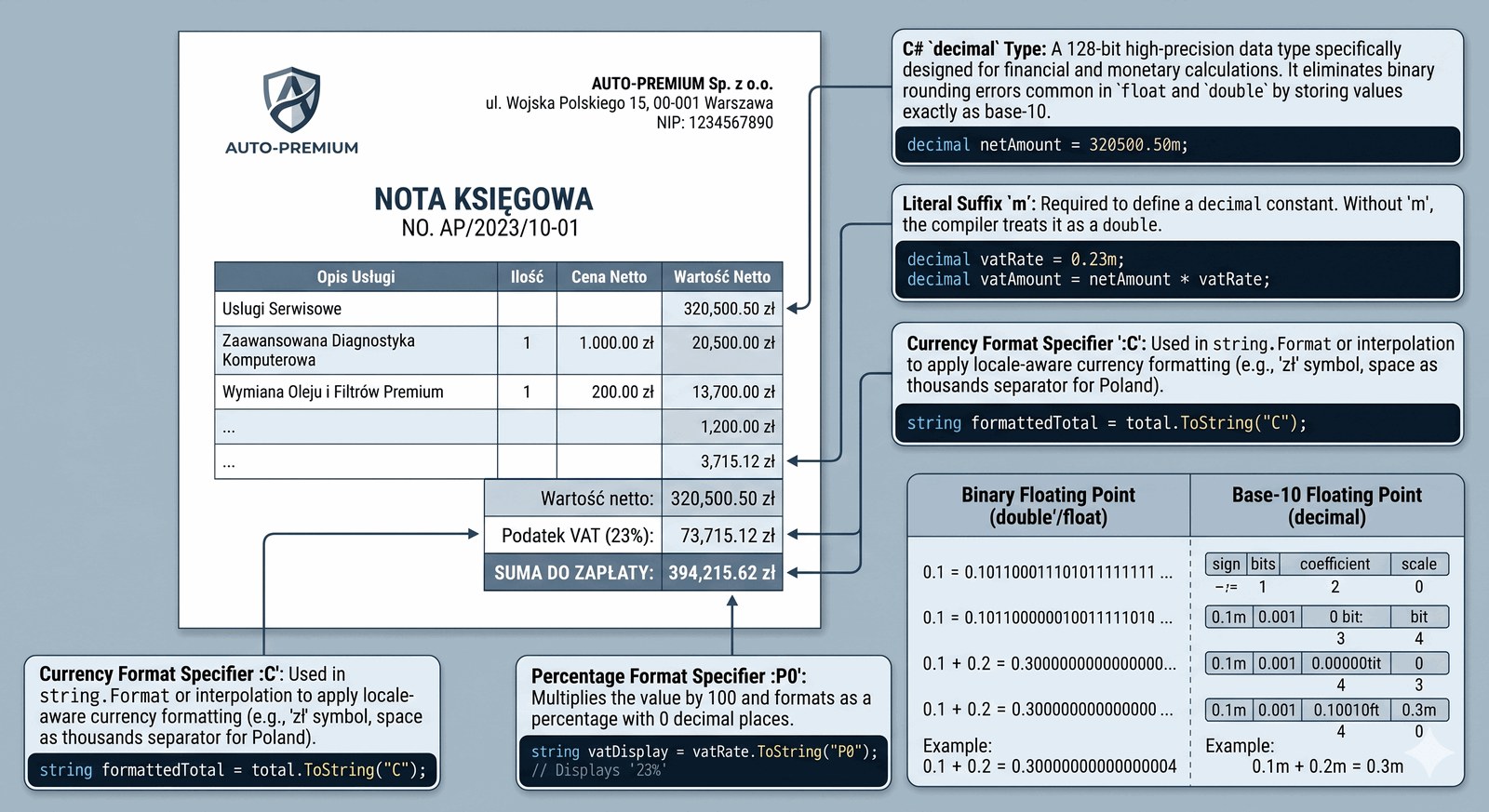
Wdrożenie bezpiecznej arytmetyki finansowej z wykorzystaniem typu High-Precision oraz nauka zaawansowanego formatowania walutowego.
Zaawansowane operacje finansowe w salonie Auto-Premium wymagają bezwzględnej dokładności, szczególnie przy naliczaniu podatku VAT od towarów luksusowych. Nawet najmniejszy błąd wynikający z binarnej reprezentacji ułamków mógłby narazić firmę na dotkliwe kary skarbowe oraz utratę zaufania klientów. Twoim zadaniem jest stworzenie generatora precyzyjnych not księgowych, który operuje na kwotach o wysokiej wartości. System musi przyjmować cenę netto, dynamicznie obliczać wartość podatku oraz sumaryczną kwotę brutto. Kluczowym wymaganiem jest, aby raport był czytelny dla międzynarodowych audytorów, dlatego symbol waluty oraz separator dziesiętny muszą być zgodne z lokalnymi ustawieniami systemowymi. Każda pozycja na fakturze musi być wyraźnie opisana i sformatowana w sposób uniemożliwiający błędną interpretację liczb. Prezentowane dane finansowe mają odzwierciedlać profesjonalizm i dbałość o detal, z których słynie marka Auto-Premium. System ten będzie wykorzystywany przy finalizacji umów sprzedaży najdroższych pojazdów w ofercie. Skupiasz się tutaj na eliminacji błędów numerycznych za pomocą dedykowanych typów danych języka C#.
Typ danych decimal w C# jest 128-bitowym typem danych, zaprojektowanym specjalnie do obliczeń finansowych i naukowych, gdzie wymagany jest brak błędów zaokrągleń charakterystycznych dla typów zmiennoprzecinkowych binarnych (jak double). W przeciwieństwie do nich, decimal przechowuje liczbę w systemie dziesiętnym, co pozwala na precyzyjne odzwierciedlenie ułamków takich jak 0.1 czy 0.2. Zakres tego typu jest mniejszy niż double, ale jego precyzja wynosi aż 28-29 cyfr znaczących. W kodzie stałe typu decimal muszą być oznaczone sufiksem m (od money), na przykład 0.23m. Operatory arytmetyczne są przeładowane dla tego typu, zapewniając bezpieczne wykonywanie dodawania czy mnożenia w domenie dziesiętnej. Do formatowania wyjścia wykorzystujemy specyfikator formatu :C (Currency), który automatycznie wykrywa kulturę systemu (lokalizację) i dodaje odpowiedni symbol waluty (np. zł, $, €) oraz separatory tysięcy. Inny użyty specyfikator, :P, służy do prezentacji wartości procentowych, automatycznie mnożąc liczbę przez 100 i dodając symbol %. Interpolacja ciągów znaków pozwala na umieszczenie tych specyfikatorów bezpośrednio po dwukropku wewnątrz klamer. Zmienne typu decimal są typami wartościowymi (Value Types), ale ze względu na swój rozmiar są nieco wolniejsze w obliczeniach procesora niż typy binarne – jest to jednak cena za absolutną precyzję. Metoda Console.WriteLine dba o to, by separator dziesiętny odpowiadał lokalnym standardom (przecinek w Polsce, kropka w USA). Należy pamiętać o poprawnym typowaniu przy operacjach mieszanych, gdyż niejawna konwersja z double na decimal nie istnieje ze względu na potencjalną utratę precyzji binarnej. Program uczy, jak budować zaufanie do systemów finansowych poprzez dobór odpowiednich narzędzi inżynierskich. W profesjonalnych systemach ERP, typ ten jest standardem przy każdej operacji na pieniądzach. Systematyczne formatowanie raportów w kolumnach z użyciem specyfikacji szerokości pola (np. {netto, 12:C}) poprawia czytelność zestawień zbiorczych. Zadanie demonstruje wyższość inżynierii precyzyjnej nad prostotą standardowych typów numerycznych.
class GeneratorFaktur
{
static void Main()
{
// Użycie typu decimal dla gwarancji precyzji finansowej
Console.Write("Wprowadź cenę netto pojazdu: ");
decimal cenaNetto = decimal.Parse(Console.ReadLine());
// Stałe podatkowe z sufiksem 'm'
decimal stawkaVat = 0.23m;
decimal kwotaVat = cenaNetto * stawkaVat;
decimal cenaBrutto = cenaNetto + kwotaVat;
// Wyświetlanie danych z użyciem specyfikatorów formatu waluty i procentu
Console.WriteLine("\n" + new string('*', 30));
Console.WriteLine(" NOTA KSIĘGOWA AUTO-PREMIUM ");
Console.WriteLine(new string('*', 30));
Console.WriteLine($"Wartość netto: {cenaNetto:C}");
Console.WriteLine($"Podatek VAT ({stawkaVat:P0}): {kwotaVat:C}");
Console.WriteLine(new string('-', 30));
Console.WriteLine($"SUMA DO ZAPŁATY: {cenaBrutto:C}");
}
}
******************************
NOTA KSIĘGOWA AUTO-PREMIUM
******************************
Wartość netto: 320 500,50 zł
Podatek VAT (23%): 73 715,12 zł
------------------------------
SUMA DO ZAPŁATY: 394 215,62 zł
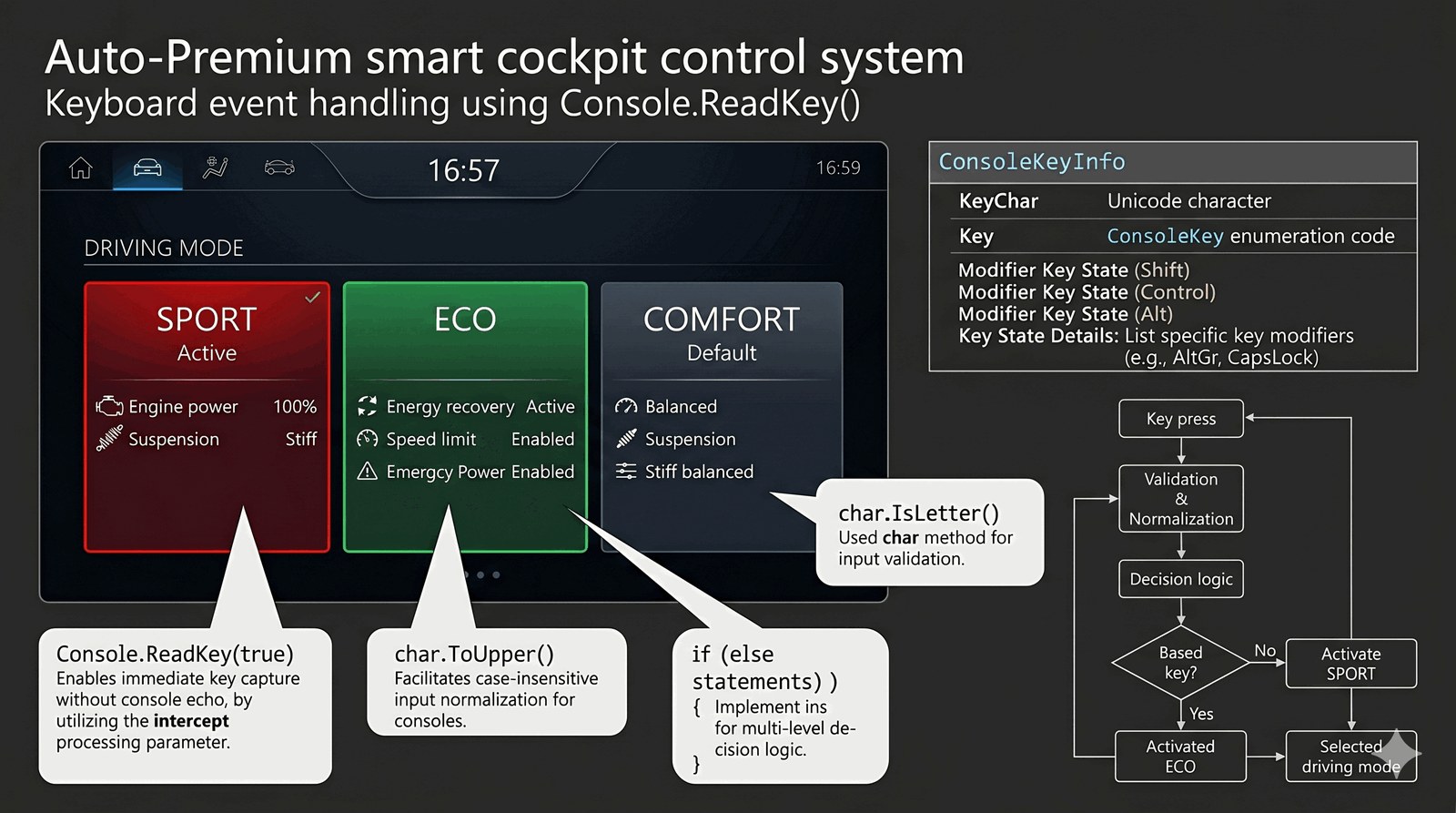
Implementacja interaktywnego interfejsu opartego na zdarzeniach klawiatury oraz analiza struktury ConsoleKeyInfo.
Nowoczesne koncepcyjne wnętrza pojazdów Auto-Premium eliminują fizyczne przyciski na rzecz dotykowych terminali i wirtualnych interfejsów sterowanych gestami lub klawiszami szybkiego dostępu. Twoim zadaniem jest stworzenie prototypu systemu operacyjnego dla inteligentnego kokpitu, który reaguje błyskawicznie na decyzje kierowcy. System musi działać w trybie bezpośrednim, co oznacza, że wybór konkretnej funkcji pojazdu następuje natychmiast po dotknięciu (naciśnięciu) klawisza, bez zbędnego potwierdzania. Program ma umożliwić przełączanie między trybami jazdy takimi jak Sport, Eco oraz Comfort, prezentując przy tym dynamiczne komunikaty diagnostyczne. Dodatkowo, system musi posiadać funkcję bezpieczeństwa, która wykrywa próby wprowadzenia niepoprawnych znaków i informuje o nich operatora. Taka responsywność interfejsu jest kluczowa dla bezpieczeństwa i komfortu podróży przy wysokich prędkościach. Każda interakcja musi być rejestrowana w logach systemowych kokpitu. Budujesz tutaj fundamenty pod User Experience klasy premium. Scenariusz ten uczy projektowania oprogramowania reagującego w czasie rzeczywistym na bodźce zewnętrzne.
Kluczowym elementem tego zadania jest metoda Console.ReadKey(bool intercept), która różni się znacząco od popularnego ReadLine. Parametr true powoduje, że naciśnięty klawisz nie jest wyświetlany (echo) w konsoli, co jest istotne przy budowie interfejsów sterujących lub pól haseł. Metoda ta zwraca strukturę ConsoleKeyInfo, która zawiera szczegółowe informacje o zdarzeniu klawiatury: właściwość KeyChar (reprezentacja znakowa Unicode), Key (kod klawisza z wyliczenia ConsoleKey) oraz status klawiszy modyfikujących (Shift, Alt, Ctrl). Typ danych char reprezentuje pojedynczy znak 16-bitowy zakodowany w formacie UTF-16, co pozwala na obsługę szerokiej gamy symboli międzynarodowych. Wykorzystujemy metodę statyczną char.ToUpper(), która zapewnia poprawną normalizację wielkości liter niezależnie od tego, czy użytkownik użył klawisza Caps Lock. Instrukcja warunkowa if analizuje logicznie wartość znaku, pozwalając na rozgałęzienie algorytmu w zależności od wyboru kierowcy. Metoda char.IsLetter() jest przykładem walidacji semantycznej danych, odróżniającej znaki alfabetu od cyfr czy symboli specjalnych. Wewnątrz instrukcji warunkowych stosujemy operatory porównania == do precyzyjnej identyfikacji opcji. Zagnieżdżone bloki kodu pozwalają na wielopoziomową logikę decyzyjną, charakterystyczną dla maszyn stanów. Należy pamiętać, że Console.ReadKey jest operacją blokującą – wątek programu zatrzymuje się w oczekiwaniu na sygnał przerwania z kontrolera klawiatury. Jest to świetny wstęp do zrozumienia programowania sterowanego zdarzeniami (Event-Driven Programming). Struktura ConsoleKeyInfo jest typem wartościowym, co oznacza, że jest kopiowana przy przekazywaniu, ale jej lekkość sprawia, że jest idealna do takich szybkich operacji. Prawidłowa obsługa znaków specjalnych chroni program przed awarią przy przypadkowym naciśnięciu klawiszy funkcyjnych. Całość tworzy interaktywną pętlę komunikacji człowiek-maszyna.
class KokpitSterowniczy
{
static void Main()
{
Console.WriteLine("AUTOPREMIUM SMART-KOKPIT v1.0");
Console.WriteLine("Dostępne tryby: [S]PORT, [E]CO, [C]OMFORT");
Console.Write("Naciśnij odpowiedni klawisz...");
// Przechwycenie klawisza bez wyświetlania go w konsoli (intercept = true)
ConsoleKeyInfo naciśniętyInfo = Console.ReadKey(true);
char znakKlawisza = char.ToUpper(naciśniętyInfo.KeyChar);
Console.WriteLine("\n" + new string('-', 20));
if (char.IsLetter(znakKlawisza))
{
if (znakKlawisza == 'S')
{
Console.ForegroundColor = ConsoleColor.Red;
Console.WriteLine("ZMIANA TRYBU: SPORT+");
Console.WriteLine("Moc silnika: 100% | Zawieszenie: Sztywne");
Console.ResetColor();
}
else if (znakKlawisza == 'E')
{
Console.ForegroundColor = ConsoleColor.Green;
Console.WriteLine("ZMIANA TRYBU: ECO-EFFICIENT");
Console.WriteLine("Odzyskiwanie energii: Aktywne | V-Max: Limitowana");
Console.ResetColor();
}
else
{
Console.WriteLine($"Aktywowano profil domyślny dla wyboru: {znakKlawisza}");
}
}
else
{
Console.WriteLine("BŁĄD SYSTEMU: Wykryto znak spoza zakresu funkcyjnego.");
}
}
}
Dostępne tryby: [S]PORT, [E]CO, [C]OMFORT
Naciśnij odpowiedni klawisz...
(Użytkownik nacisnął klawisz 'S')
--------------------
ZMIANA TRYBU: SPORT+
Moc silnika: 100% | Zawieszenie: Sztywne
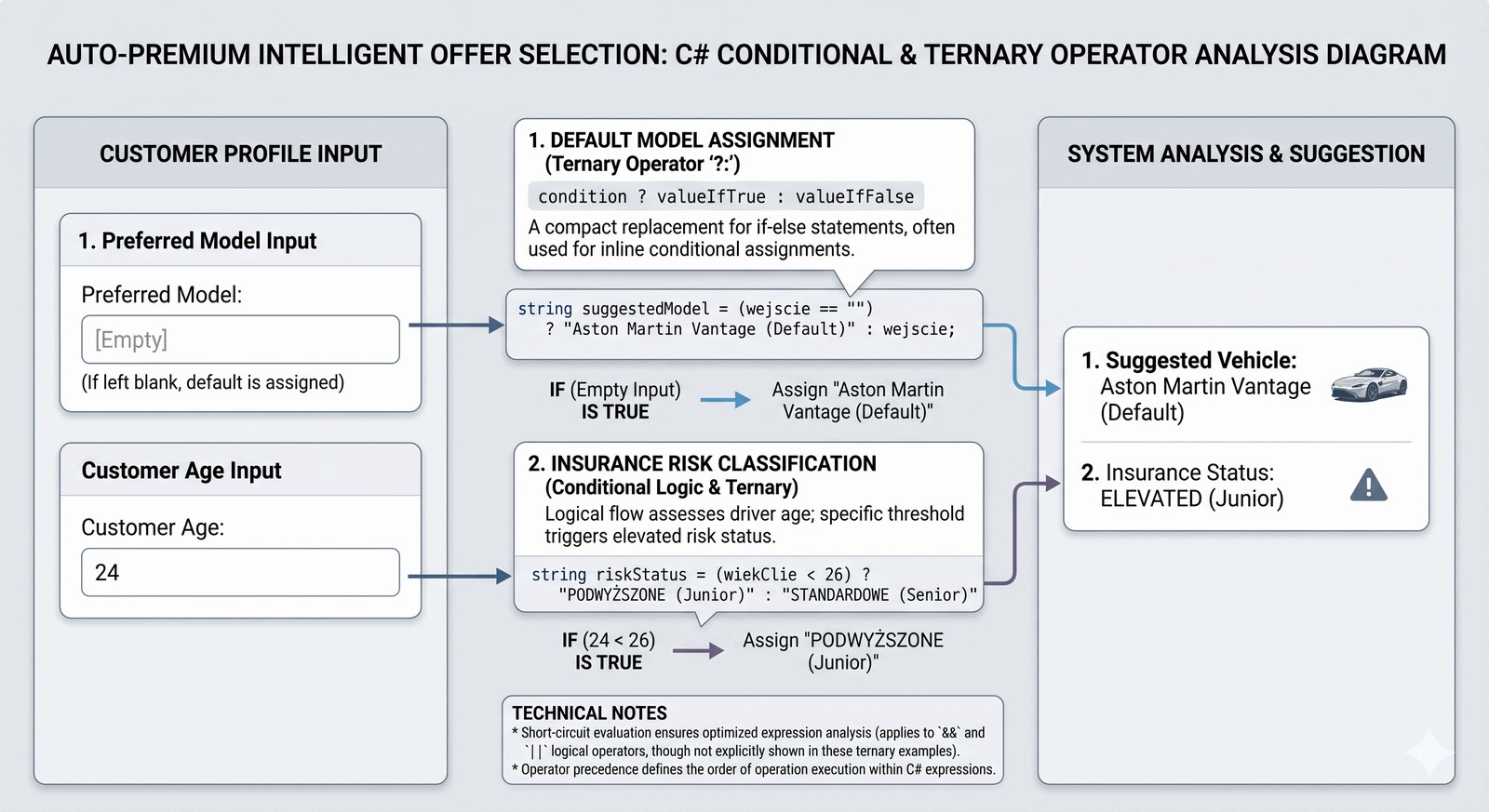
Wdrożenie zwięzłych mechanizmów decyzyjnych za pomocą operatorów warunkowych i null-coalescing w celu uproszczenia przepływu danych.
Inteligentny system doradczy w salonie Auto-Premium ma za zadanie automatycznie sugerować najlepszy model pojazdu w przypadku, gdy klient nie sprecyzował swoich oczekiwań w formularzu. System analizuje wejście tekstowe i w razie braku konkretnych danych (pusty ciąg znaków), musi bezzwłocznie zaproponować flagowy model marki, zapewniając ciągłość procesu sprzedaży. Równolegle, system monitoruje wiek potencjalnego nabywcy, aby automatycznie dostosować politykę ubezpieczeniową i ryzyko kredytowe. Twoim zadaniem jest zaimplementowanie logiki, która bez rozbudowanych struktur blokowych dokona błyskawicznej oceny profilu klienta. Efektem ma być spersonalizowana odpowiedź systemu, która wyświetli sugerowany samochód oraz przypisany poziom ryzyka (np. wysoki dla młodych kierowców). Taka optymalizacja kodu jest kluczowa w wydajnych aplikacjach webowych i mobilnych, gdzie czytelność idzie w parze z szybkością działania. Salon stawia na innowacje, dlatego Twój kod musi odzwierciedlać najnowocześniejsze standardy języka C#. Budujesz tutaj inteligentny filtr danych, który stanowi mózg elektronicznego asystenta sprzedaży. Scenariusz ten łączy pragmatykę biznesową z elegancją składniową.
Zadanie koncentruje się na dwóch potężnych operatorach: trójargumentowym operatorze warunkowym ? : oraz operatorze null-coalescing ??. Operator trójargumentowy jest skróconą formą instrukcji if-else, która pozwala na przypisanie wartości do zmiennej w jednej linii na podstawie warunku logicznego. Składa się on z trzech części: wyrażenia boolowskiego, wartości zwracanej przy prawdzie i wartości zwracanej przy fałszu. Zwiększa to czytelność kodu poprzez eliminację zbędnych klamer i wielokrotnych instrukcji przypisania. Operator ?? (null-coalescing) służy do obsługi wartości brakujących (null). W tym przypadku symulujemy go poprzez sprawdzenie pustego stringa za pomocą operatora warunkowego, gdyż Console.ReadLine() rzadko zwraca czysty null. Należy zrozumieć mechanizm "short-circuiting", gdzie w operatorach logicznych druga część warunku może nie zostać sprawdzona, jeśli wynik jest już znany. W C# operatory te są niezwykle wydajne, gdyż kompilator optymalizuje je do prostych skoków w kodzie maszynowym. Wykorzystanie tych konstrukcji pozwala na budowanie tzw. płynnego kodu (Fluent Code). Właściwość string.IsNullOrEmpty() byłaby tu alternatywą, lecz operator trójargumentowy daje większą kontrolę nad procesem mapowania wartości. Zmienne lokalne, takie jak model czy ryzyko, posiadają ograniczony zasięg (scope) do metody Main, co sprzyja bezpieczeństwu pamięci. Warto zauważyć, że operator ? : ma niższą priorytetowość niż operatory arytmetyczne, co wymaga uwagi przy budowaniu złożonych wyrażeń. Zastosowanie tych technik redukuje tzw. "Code Smell" w postaci nadmiernie rozbudowanych drabinek if-else. Program uczy, jak mapować wymagania biznesowe (np. próg wieku 25 lat) bezpośrednio na zwięzłe wyrażenia logiczne. Precyzyjne formatowanie komunikatów z użyciem stałych tekstowych pomaga w standaryzacji odpowiedzi systemu. Pamięć alokowana dla wyników tych operacji jest zarządzana automatycznie przez Garbage Collector, jednak optymalna logika minimalizuje liczbę tworzonych obiektów tymczasowych. Rezultatem jest kod, który jest nie tylko funkcjonalny, ale i estetycznie poprawny z punktu widzenia doświadczonego inżyniera C#.
class DoradcaSprzedazy
{
static void Main()
{
Console.Write("Preferowany model (Enter dla braku wyboru): ");
string wejscie = Console.ReadLine();
// OPERATOR WARUNKOWY: Przypisanie modelu domyślnego, jeśli wejście jest puste
string rekomendacja = (wejscie == "") ? "Aston Martin Vantage (Default)" : wejscie;
Console.Write("Wiek klienta: ");
int wiekKlienta = int.Parse(Console.ReadLine());
// OPERATOR TRÓJARGUMENTOWY: Klasyfikacja ryzyka ubezpieczeniowego
string profilRyzyka = (wiekKlienta < 26) ? "PODWYŻSZONE (Junior)" : "STANDARDOWE (Senior)";
// Wyświetlenie końcowej karty rekomendacji
Console.WriteLine("\n--- KARTA ANALIZY AUTO-PREMIUM ---");
Console.WriteLine($"Sugerowany pojazd: {rekomendacja}");
Console.WriteLine($"Status ubezpieczyciela: {profilRyzyka}");
}
}
Wiek klienta: 24
--- KARTA ANALIZY AUTO-PREMIUM ---
Sugerowany pojazd: Aston Martin Vantage (Default)
Status ubezpieczyciela: PODWYŻSZONE (Junior)
Zastosowanie pętli for do przetwarzania sekwencyjnego danych oraz biegłość w operacjach akumulacji wartości w zmiennych liczbowych.
Dział inżynieryjny Auto-Premium prowadzi rygorystyczne testy wydajności paliwowej nowych hybrydowych jednostek napędowych. Każdy pojazd musi przejść serię 6 znormalizowanych prób drogowych w różnych warunkach atmosferycznych. Twoim zadaniem jest opracowanie modułu telemetrycznego, który będzie zbierał dane o spalaniu (litry na 100 km) z każdego przejazdu. Program musi działać w trybie interaktywnym, prosząc operatora o wprowadzenie wyników jeden po drugim. Kluczowym wymaganiem jest obliczenie sumarycznego zużycia paliwa oraz wyciągnięcie dokładnej średniej arytmetycznej z całego cyklu testowego. System musi być przygotowany na liczby rzeczywiste, gdyż wyniki często podawane są z precyzją do dwóch miejsc po przecinku. Dzięki temu narzędziu inżynierowie mogą błyskawicznie ocenić, czy dany egzemplarz spełnia wyśrubowane normy emisji spalin. Wykorzystasz tutaj mechanizmy pętli, aby uniknąć redundancji w kodzie i zapewnić skalowalność algorytmu w przyszłości. Twoja praca bezpośrednio wpłynie na optymalizację ekologiczną floty Auto-Premium. System uczy Cię obróbki serii danych pomiarowych bez użycia zaawansowanych struktur kolekcyjnych. Skupiasz się na czystej logice iteracyjnej.
W zadaniu wykorzystujemy pętlę for, która jest podstawową konstrukcją iteracyjną w języku C#, pozwalającą na wykonanie bloku kodu określoną liczbę razy. Pętla składa się z trzech sekcji: inicjalizacji licznika, warunku kontynuacji oraz kroku iteracji (inkrementacji). Inicjalizacja int i = 1 tworzy zmienną sterującą na stosie, która jest dostępna wyłącznie wewnątrz bloku pętli (ograniczony zasięg). Warunek i <= 6 jest sprawdzany przed każdym wykonaniem obrotu pętli; jeśli zwróci false, pętla zostaje natychmiast przerwana. Akumulacja danych odbywa się w zmiennej sumaSpalania typu double, która działa jako akumulator (sumator). Bardzo ważne jest zainicjalizowanie akumulatora wartością 0 przed wejściem do pętli, w przeciwnym razie kompilator zgłosi błąd użycia nieprzypisanej zmiennej. Wewnątrz pętli stosujemy operator przypisania złożonego +=, który jest syntaktycznym skrótem dla suma = suma + wartosc. Metoda double.Parse() służy do konwersji tekstu z konsoli na liczbę zmiennoprzecinkową, uwzględniając lokalne separatory dziesiętne. Średnia arytmetyczna obliczana jest po wyjściu z pętli poprzez pojedyncze dzielenie sumy przez liczbę iteracji. Zastosowanie specyfikatora formatu :F2 w interpolacji zapewnia, że wynik zostanie zaokrąglony do dwóch miejsc po przecinku, co jest standardem w raportach inżynierskich. Należy zwrócić uwagę na koszt wydajnościowy pętli – w tym przypadku jest on minimalny, ale dobra praktyka nakazuje minimalizowanie operacji wejścia/wyjścia wewnątrz ciasnych pętli. Pętla for jest tutaj lepszym wyborem niż while, ponieważ liczba powtórzeń jest z góry znana i stała. Zmienna sterująca i jest często wykorzystywana do numerowania komunikatów tekstowych wyświetlanych użytkownikowi. Program demonstruje, jak proste struktury sterujące mogą zastąpić setki linii powtarzalnego kodu. Wiedza o tym, jak procesor zarządza skokami (JUMP) na poziomie niskopoziomowym, pomaga pisać bardziej optymalne pętle w przyszłości. Każdy element składni przybliża studenta do zrozumienia algorytmiki sekwencyjnej.
class AnalizatorTelemetrii
{
static void Main()
{
double sumaSpalania = 0.0;
const int liczbaProb = 6;
Console.WriteLine("=== MODUŁ ANALIZY WYDAJNOŚCI PALIWOWEJ ===");
Console.WriteLine($"Rozpoczynam zbieranie danych z {liczbaProb} przejazdów.\n");
for (int i = 1; i <= liczbaProb; i++)
{
Console.Write($"Wprowadź wynik testu {i} [L/100km]: ");
// Odczytujemy dane i dodajemy do akumulatora sumy
double aktualnyWynik = double.Parse(Console.ReadLine());
sumaSpalania += aktualnyWynik;
}
// Finalne przeliczenie statystyk po zakończeniu cyklu iteracyjnego
double srednieSpalanie = sumaSpalania / liczbaProb;
Console.WriteLine(new string('=', 40));
Console.WriteLine($"Całkowite zużycie: {sumaSpalania:F2} L");
Console.WriteLine($"Średnie spalanie: {srednieSpalanie:F2} L/100km");
Console.WriteLine(new string('=', 40));
}
}
Rozpoczynam zbieranie danych z 6 przejazdów.
Wprowadź wynik testu 1 [L/100km]: 8,2
Wprowadź wynik testu 2 [L/100km]: 7,9
Wprowadź wynik testu 3 [L/100km]: 8,5
Wprowadź wynik testu 4 [L/100km]: 8,1
Wprowadź wynik testu 5 [L/100km]: 7,8
Wprowadź wynik testu 6 [L/100km]: 8,3
========================================
Całkowite zużycie: 48,80 L
Średnie spalanie: 8,13 L/100km
========================================

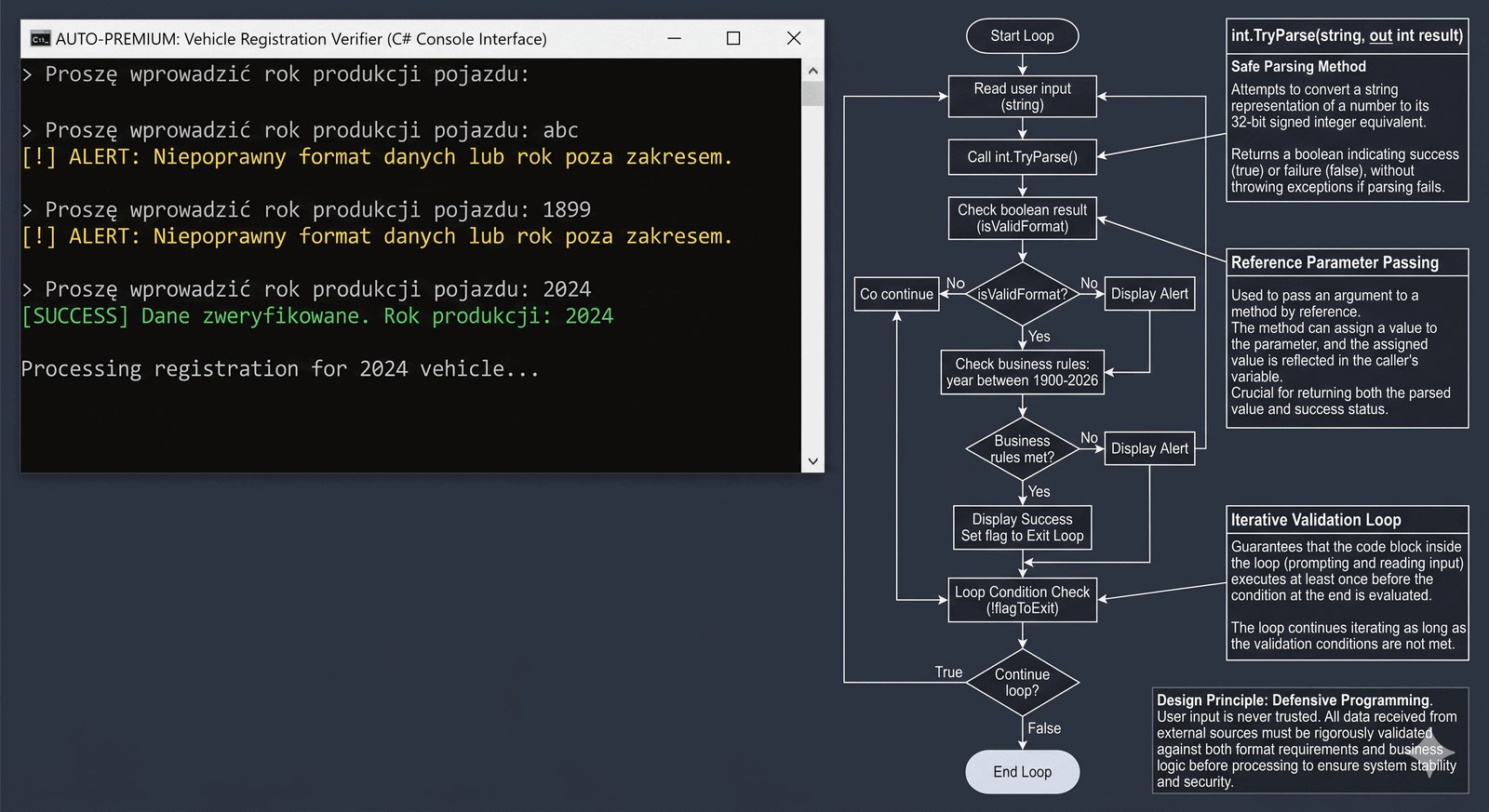
Zapewnienie odporności aplikacji na błędy wejścia poprzez wykorzystanie pętli warunkowej oraz bezpiecznych metod parsowania z parametrami wyjściowymi.
W procesie certyfikacji używanych pojazdów w programie "Auto-Premium Approved", kluczowym parametrem jest data pierwszej rejestracji oraz autentyczny rok produkcji. Niejednokrotnie zdarza się, że podczas szybkiego wprowadzania danych przez rzeczoznawców dochodzi do literówek lub błędów formatowania, co w standardowych systemach powoduje krytyczne awarie bazy danych. Twoim zadaniem jest stworzenie inteligentnego modułu walidacji, który nie pozwoli przejść do kolejnego etapu, dopóki w systemie nie znajdzie się poprawna, numeryczna wartość roku. Program musi cierpliwie informować użytkownika o pomyłce i prosić o ponowną próbę, eliminując tym samym ryzyko przestojów w pracy biura. System musi być na tyle odporny, by poradzić sobie z przypadkowym wpisaniem znaków specjalnych czy liter w pola numeryczne. Takie podejście gwarantuje integralność danych w całym łańcuchu sprzedażowym salonu. Twoja praca chroni system przed błędami ludzkimi, które są nieuniknione w dynamicznym środowisku handlowym. Uczysz się pisać oprogramowanie "bulletproof", które jest standardem w aplikacjach przemysłowych i finansowych. Ten moduł to strażnik czystości danych w Twojej aplikacji.
Centralnym punktem tego zadania jest mechanizm int.TryParse(string s, out int result), który jest bezpieczną alternatywą dla metody Parse. Metoda ta zwraca wartość typu bool, wskazującą czy operacja zamiany tekstu na liczbę zakończyła się sukcesem, co zapobiega rzucaniu wyjątków (brak awarii programu). Kluczowym słowem jest tu out, które oznacza przekazanie parametru przez referencję wyjściową – wynik konwersji zostanie zapisany w podanej zmiennej pod warunkiem pomyślnego parsowania. Wykorzystujemy pętlę do-while, która gwarantuje wykonanie bloku kodu przynajmniej raz, a jej warunek końcowy sprawdzany jest dopiero po wykonaniu iteracji. Wewnątrz pętli stosujemy instrukcję if z operatorem negacji !, aby zareagować tylko w przypadku niepowodzenia konwersji. Zmienna logiczna sukces steruje przepływem pętli, tworząc tzw. pętlę nieskończoną z warunkiem wyjścia. To podejście jest znacznie bardziej wydajne i eleganckie niż stosowanie bloków try-catch dla prostych operacji wejścia. Należy zauważyć, że zmienna przekazywana przez out nie musi być zainicjalizowana przed wywołaniem metody, co upraszcza deklaracje. Pamiętaj o obsłudze zakresów danych – samo sprawdzenie czy to liczba to połowa sukcesu, warto też dodać warunki sprawdzające czy rok mieści się w logicznym przedziale (np. 1900-2026). Zastosowanie metody Console.ReadLine() zapewnia pobranie świeżego wejścia w każdej iteracji pętli. Całość konstrukcji uczy defensywnego stylu programowania (Defensive Programming), który zakłada, że użytkownik zawsze może popełnić błąd. Profesjonalne aplikacje biznesowe opierają się na takich weryfikatorach na każdym etapie przetwarzania. Wiedza o tym, jak powstają błędy parsowania, pozwala lepiej projektować formularze w interfejsach graficznych. Mechanizm ten jest wspólny dla wszystkich typów numerycznych w .NET (double, decimal, long itd.), co nadaje mu charakter uniwersalny.
class WeryfikatorDanych
{
static void Main()
{
Console.WriteLine("AUTORYZOWANY REJESTR POJAZDÓW UŻYWANYCH v2.0");
int zweryfikowanyRok = 0;
bool czyPoprawne = false;
// Pętla walidacyjna działająca do skutku
do
{
Console.Write("Proszę wprowadzić rok produkcji pojazdu: ");
string wejscieUzytkownika = Console.ReadLine();
// Próba bezpiecznego parsowania z parametrem out
czyPoprawne = int.TryParse(wejscieUzytkownika, out zweryfikowanyRok);
// Sprawdzenie warunków dodatkowych (zakres biznesowy)
if (!czyPoprawne || zweryfikowanyRok < 1900 || zweryfikowanyRok > 2026)
{
Console.ForegroundColor = ConsoleColor.Yellow;
Console.WriteLine("[!] ALERT: Niepoprawny format danych lub rok poza zakresem.");
Console.ResetColor();
czyPoprawne = false; // Wymuszamy powrót pętli dla złego zakresu
}
} while (!czyPoprawne);
Console.WriteLine($"\n[SUCCESS] Dane zweryfikowane. Rok produkcji: {zweryfikowanyRok}");
}
}
Proszę wprowadzić rok produkcji pojazdu: rocznik 2018
[!] ALERT: Niepoprawny format danych lub rok poza zakresem.
Proszę wprowadzić rok produkcji pojazdu: 2024
[SUCCESS] Dane zweryfikowane. Rok produkcji: 2024
Opanowanie konstrukcji pętli wielopoziomowych oraz technik generowania grafiki ASCII do celów analitycznych.
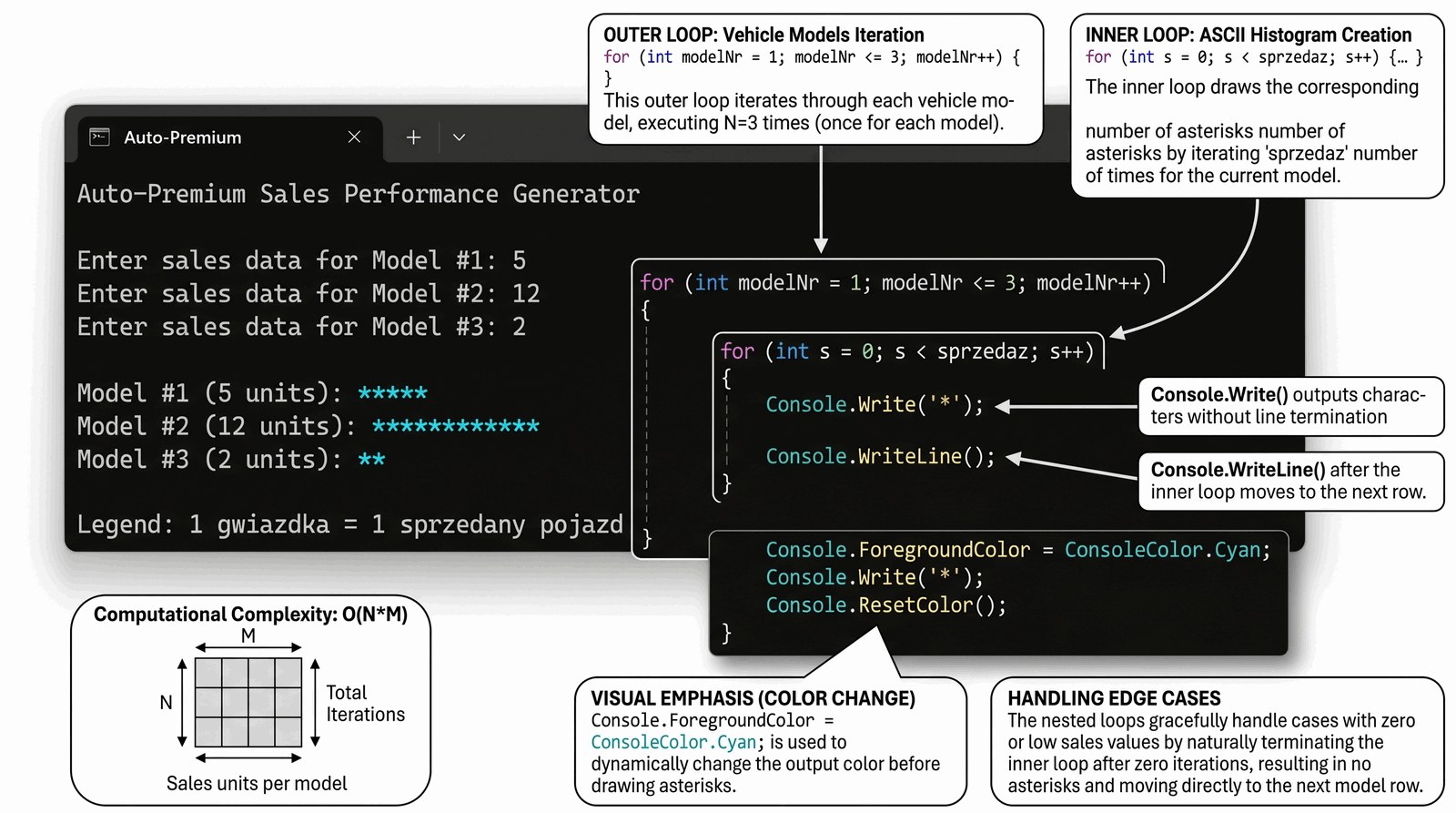
Zarząd salonu Auto-Premium wymaga czytelnych, tekstowych wizualizacji wyników sprzedaży miesięcznej, które mogą być drukowane bezpośrednio z terminali serwisowych. Tradycyjne tabele z liczbami są często mało czytelne przy szybkiej analizie trendów, dlatego Twoim zadaniem jest stworzenie generatora poziomych histogramów. Program ma za zadanie pobrać liczbę sprzedanych egzemplarzy dla trzech kluczowych modeli z oferty luksusowej. Następnie, system musi wygenerować barwną reprezentację graficzną, gdzie każda sprzedana sztuka odpowiada jednemu znakowi wizualnemu. Takie podejście pozwala na natychmiastowe porównanie popularności różnych aut bez konieczności zagłębiania się w surowe dane numeryczne. Wizualizacja musi być estetyczna i profesjonalnie oddzielać poszczególne rekordy danych. Algorytm rysujący musi być na tyle elastyczny, by radzić sobie z różnymi wartościami sprzedaży, od jednostkowych po dziesiątki sztuk. Jest to doskonały przykład wykorzystania prostych narzędzi tekstowych do budowy zaawansowanych raportów biznesowych w środowisku CLI. Praca ta uczy Cię myślenia algorytmicznego opartego na powtarzalności operacji rysowania.
W zadaniu wykorzystujemy zagnieżdżenie pętli (nested loops), czyli sytuację, w której jedna pętla for znajduje się wewnątrz bloku innej pętli for. Pętla zewnętrzna służy do iteracji po wierszach danych (w naszym przypadku po kolejnych modelach aut), natomiast pętla wewnętrzna odpowiada za operacje w poziomie – rysowanie odpowiedniej liczby znaków graficznych. Każdy obieg pętli zewnętrznej powoduje pełne wykonanie wszystkich powtórzeń pętli wewnętrznej. Jest to mechanizm o złożoności obliczeniowej kwadratowej O(N*M), co w przypadku małych danych konsolowych jest niezauważalne, ale stanowi ważny koncept teoretyczny. Bardzo istotne jest użycie metody Console.Write() wewnątrz pętli wewnętrznej, aby znaki były drukowane obok siebie bez przejścia do nowej linii. Po zakończeniu pracy pętli wewnętrznej, sterowanie wraca do pętli zewnętrznej, która wywołuje Console.WriteLine(), aby przygotować terminal na kolejny wiersz raportu. Zmienne sterujące w obu pętlach (zwyczajowo i oraz j) muszą mieć unikalne nazwy, aby nie dochodziło do konfliktów logicznych w zakresie zmiennych. Kod demonstruje również odczyt danych wejściowych w każdym kroku pętli zewnętrznej, co pozwala na dynamiczne sterowanie limitami pętli wewnętrznej. Wykorzystujemy typ int do przechowywania liczników oraz wartości sprzedaży, co zapewnia optymalną wydajność operacji skoku. Tekstowe separatory i nagłówki pomagają w budowie strukturalnej wizualizacji. Możliwość zmiany koloru czcionki (Console.ForegroundColor) dodatkowo wzbogaca wizualnie generowany histogram. Pamiętaj o obsłudze bardzo niskich lub zerowych wartości, które mogą skutkować pustymi wierszami. Całość algorytmu uczy precyzyjnego zarządzania kursorem w środowisku tekstowym. Takie wzorce są powszechnie stosowane przy generowaniu wykresów, macierzy oraz w grafice komputerowej 2D. Zrozumienie relacji między licznikiem zewnętrznym a wewnętrznym to fundament programowania strukturalnego.
class GeneratorHistogramow
{
static void Main()
{
Console.WriteLine("=== MODUŁ WIZUALIZACJI SPRZEDAŻY AUTO-PREMIUM ===");
Console.WriteLine("Wprowadź liczbę sprzedaży dla 3 modeli flagowych:\n");
// Pętla zewnętrzna: iteracja po rekordach (modelach)
for (int modelNr = 1; modelNr <= 3; modelNr++)
{
Console.Write($"Model #{modelNr} - liczba: ");
int sprzedaz = int.Parse(Console.ReadLine());
Console.Write("Wykres: [");
// Pętla zagnieżdżona: rysowanie gwiazdek odpowiadających sprzedaży
for (int s = 0; s < sprzedaz; s++)
{
Console.ForegroundColor = ConsoleColor.Cyan;
Console.Write("*");
}
Console.ResetColor();
Console.WriteLine("]");
}
Console.WriteLine("\nLegenda: 1 gwiazdka = 1 sprzedany pojazd.");
}
}
Wprowadź liczbę sprzedaży dla 3 modeli flagowych:
Model #1 - liczba: 5
Wykres: [*****]
Model #2 - liczba: 12
Wykres: [************]
Model #3 - liczba: 2
Wykres: [**]
Legenda: 1 gwiazdka = 1 sprzedany pojazd.
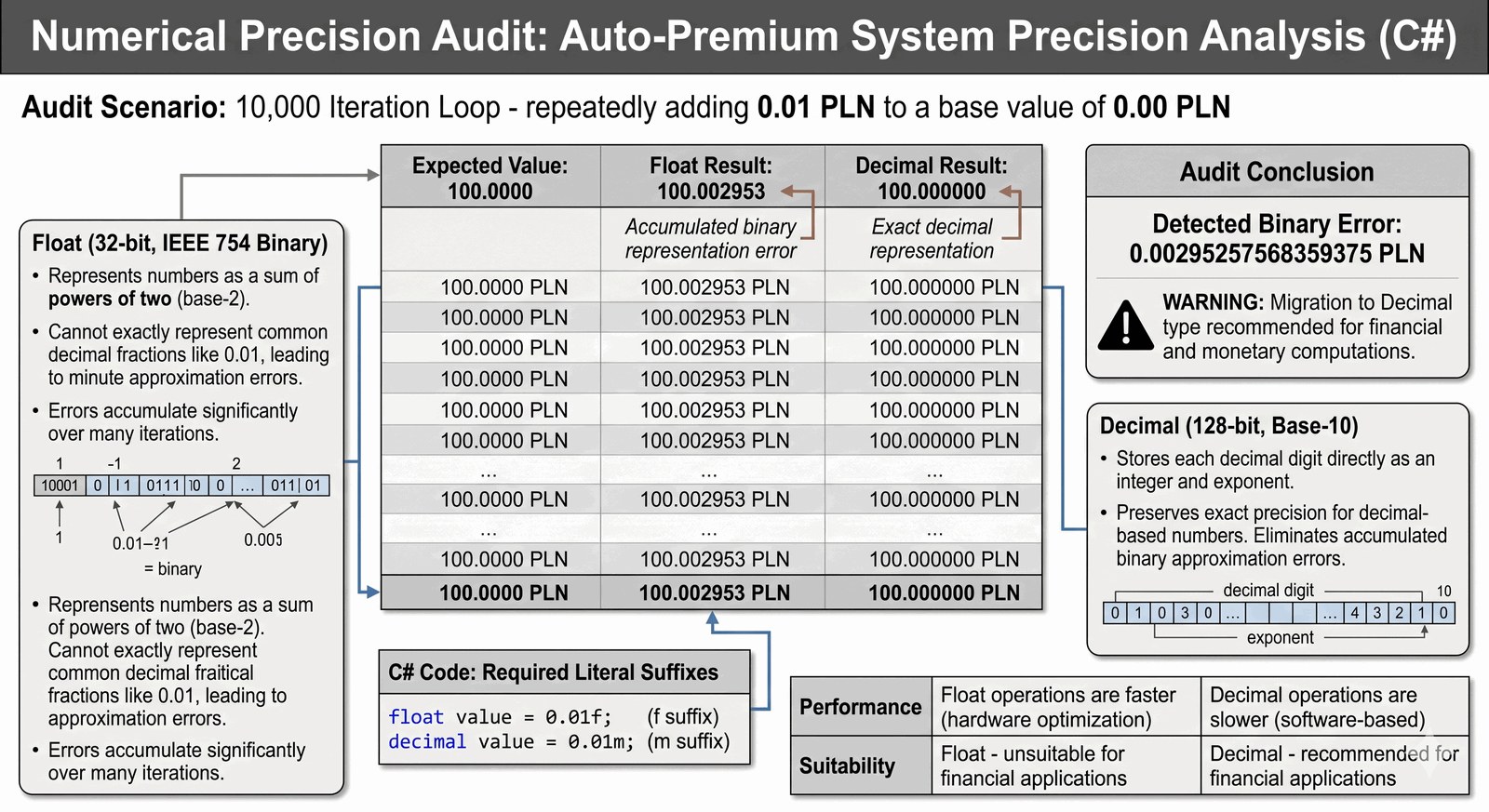
Weryfikacja różnic w implementacji arytmetyki zmiennoprzecinkowej oraz świadomy wybór typów danych dla systemów krytycznych biznesowo.
Zarząd Auto-Premium zlecił audyt techniczny systemów finansowych po wykryciu drobnych nieścisłości w zbiorczych raportach rocznych. Podejrzenie padło na niewłaściwy dobór typów danych w algorytmach kumulujących setki tysięcy mikro-transakcji serwisowych. Jako ekspert ds. jakości oprogramowania, musisz przeprowadzić test porównawczy, który ostatecznie rozstrzygnie spór między wydajnością a dokładnością. Twoim zadaniem jest napisanie symulatora, który 10 tysięcy razy doda małą wartość (np. 1 grosz) do sumatora, stosując równolegle typy float oraz decimal. Wynik końcowy ma zostać zestawiony z oczekiwaną matematycznie wartością, ujawniając tym samym naturę błędów binarnych w typach zmiennoprzecinkowych. Taki audyt jest kluczowy dla zachowania integralności finansowej grupy i określenia standardów kodowania dla nowych modułów ERP. Wykazana różnica będzie koronnym dowodem na konieczność stosowania bardziej zasobożernych, ale precyzyjnych typów dziesiętnych. Salon stawia na pełną transparentność finansową, dlatego Twój raport musi być niepodważalny technicznie. Zadanie to kształtuje świadomość inżynierską w zakresie niskopoziomowej reprezentacji liczb w procesorze.
To zadanie konfrontuje ze sobą dwa fundamentalnie różne podejścia do zapisu ułamków: float (system binarny, 32 bity, IEEE 754) oraz decimal (system dziesiętny, 128 bitów). Typ float reprezentuje liczbę jako sumę potęg dwójki, co sprawia, że wiele ułamków dziesiętnych (np. 0.01) nie ma swojej dokładnej reprezentacji binarnej i jest przechowywane jako przybliżenie. W wyniku wielokrotnych operacji dodawania (+=), te minimalne błędy przybliżenia kumulują się, prowadząc do widocznego dryftu wyniku końcowego. Typ decimal eliminuje ten efekt, gdyż przechowuje liczbę w postaci dziesiętnej (każda cyfra po przecinku ma swoją reprezentację), co jest identyczne z ludzkim sposobem liczenia. W pętli for wykonujemy 10 000 iteracji, co wystarcza, aby błąd typu float stał się mierzalny dla człowieka. Wykorzystujemy literały f dla typu float oraz m dla typu decimal, informując tym samym kompilator o pożądanym sposobie traktowania stałych liczbowych. Wypisanie wyników w konsoli z użyciem interpolacji demonstruje różnicę w precyzji wyświetlanej – decimal kończy się na zerach, podczas gdy float pokazuje "ogon" błędnych cyfr. Należy podkreślić aspekt wydajnościowy: operacje na float są wykonywane bezpośrednio przez jednostkę FPU procesora i są znacznie szybsze. Jednak w aplikacjach biznesowych bezpieczeństwo danych finansowych jest priorytetem nad szybkością mikro-sekundową. Pętla sterująca zapewnia identyczne warunki dla obu testowanych typów, co czyni eksperyment rzetelnym. Wynik symulacji uczy, że domniemana "dokładność" komputera jest ograniczona zastosowanym modelem matematycznym. Zrozumienie tego zjawiska pozwala unikać najczęstszych błędów w systemach bankowych i e-commerce. Zmienna i w pętli służy tu jedynie jako licznik cykli, nie wpływając bezpośrednio na obliczenia arytmetyczne. Program stanowi ważne ostrzeżenie przed bezkrytycznym ufaniem standardowym typom zmiennoprzecinkowym w poważnej inżynierii programowania.
class AudytorPrecyzji
{
static void Main()
{
Console.WriteLine("=== AUDYT PRECYZJI NUMERYCZNEJ AUTO-PREMIUM ===");
float sumaF = 0.0f;
decimal sumaD = 0.0m;
const int operacje = 10000;
Console.WriteLine($"Sumowanie wartości 0.01 przez {operacje} cykli...\n");
for (int i = 0; i < operacje; i++)
{
sumaF += 0.01f;
sumaD += 0.01m;
}
// Prezentacja audytu porównawczego
Console.WriteLine("WYNIKI EKSPERYMENTU:");
Console.WriteLine($"Wartość oczekiwana: 100,0000");
Console.WriteLine($"Wynik (Float): {sumaF:F6}");
Console.WriteLine($"Wynik (Decimal): {sumaD:F6}");
decimal roznica = (decimal)sumaF - sumaD;
Console.WriteLine("\nWNIOSEK AUDYTU:");
Console.WriteLine($"Wykryty błąd binarny: {roznica} PLN");
if (roznica != 0) Console.WriteLine("OSTRZEŻENIE: Zaleca się migrację na typ Decimal!");
}
}
Sumowanie wartości 0.01 przez 10000 cykli...
WYNIKI EKSPERYMENTU:
Wartość oczekiwana: 100,0000
Wynik (Float): 100,002953
Wynik (Decimal): 100,000000
WNIOSEK AUDYTU:
Wykryty błąd binarny: 0,00295257568359375 PLN
OSTRZEŻENIE: Zaleca się migrację na typ Decimal!