Niniejszy materiał koncentruje się na efektywnym grupowaniu danych oraz algorytmach ich przetwarzania. Zrozumienie różnic między tablicami statycznymi a kolekcjami dynamicznymi jest kluczowe dla optymalizacji zużycia pamięci i wydajności aplikacji biznesowych.
Przewodnik po zagadnieniach
- Zarządzanie flotą pojazdów - Tablice jednowymiarowe
- Wielowymiarowa inwentaryzacja salonu - Tablice dwu i trójwymiarowe
- Harmonogram działu serwisowego - Tablice nieregularne (Jagged)
- Dynamiczny system rezerwacji - Kolekcje typu List
- Cyfrowy katalog części zamiennych - Słowniki (Dictionary)
- Walidacja numerów identyfikacyjnych - Operacje na stringach
- Archiwizacja raportów dziennych - Zapis i odczyt plików tekstowych
- Serializacja bazy konfiguracji - Pliki binarne i typ wyliczeniowy
- System bezpiecznych kalkulacji - Obsługa wyjątków (Try-Catch)
- Inteligentny system filtrowania - Podstawy LINQ i klasa Random
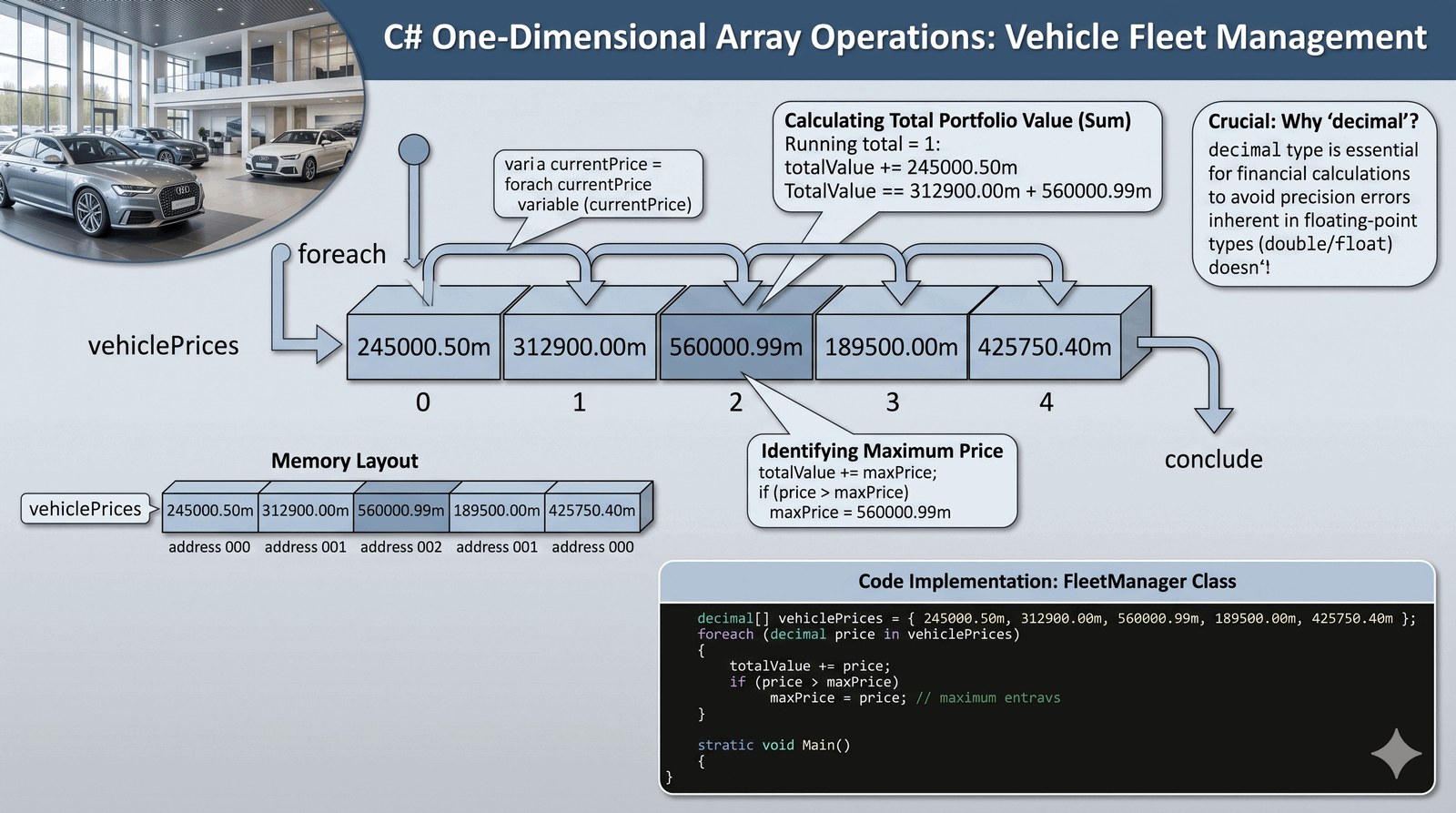
Opanowanie podstaw deklaracji, inicjalizacji oraz iteracji po tablicach jednowymiarowych w celu agregacji danych liczbowych o dużej precyzji.
Salon luksusowych samochodów Auto-Premium potrzebuje modułu do szybkiego zestawienia cen pojazdów znajdujących się aktualnie na ekspozycji głównej. Dane te są kluczowe dla doradców klienta, którzy muszą błyskawicznie podać przedział cenowy dostępnej floty podczas rozmów z inwestorami. Twoim zadaniem jest stworzenie programu, który przechowuje ceny 5 flagowych modeli w tablicy, a następnie oblicza ich sumaryczną wartość oraz identyfikuje najdroższy egzemplarz. System musi być przygotowany na precyzyjne kwoty, dlatego wybór odpowiedniego typu danych pieniężnych jest tu bezwzględnie wymagany. Raport końcowy powinien być czytelny i profesjonalny, odzwierciedlając prestiż salonu, w którym każda złotówka ma znaczenie. Każdy etap przetwarzania danych w tablicy musi być udokumentowany komentarzem, aby ułatwić zrozumienie logiki przyszłym deweloperom systemu CRM. Taka struktura danych pozwala na efektywne zarządzanie większymi zbiorami informacji, eliminując ryzyko błędów przy ręcznym podliczaniu. Budujesz tutaj pierwszy poziom cyfryzacji inwentarza salonu, co jest fundamentem nowoczesnego handlu autami segmentu premium. Program ma za zadanie zautomatyzować generowanie raportów dziennych dla zarządu firmy.
Tablica (array) w środowisku .NET jest obiektem przechowującym stałą liczbę elementów tego samego typu, co czyni ją strukturą typowaną statycznie. Jest ona alokowana w sposób ciągły w pamięci sterty (Heap), co zapewnia niezwykle szybki dostęp do elementów poprzez ich indeksy, realizowany w czasie stałym O(1). W C# indeksowanie tablic zaczyna się zawsze od zera, co oznacza, że dla tablicy o rozmiarze N, ostatni element ma indeks N-1. Do iteracji po zbiorze danych wykorzystujemy tutaj pętlę foreach, która jest bezpieczniejsza od standardowej pętli for, ponieważ wewnętrznie zarządza licznikiem i chroni programistę przed najczęstszym błędem przekroczenia zakresu (IndexOutOfRangeException). Wykorzystanie typu decimal gwarantuje brak błędów zaokrągleń ułamkowych, co w systemach finansowych jest standardem de facto. Inicjalizacja tablicy może odbywać się bezpośrednio przy deklaracji za pomocą nawiasów klamrowych, co znacząco poprawia czytelność kodu inicjalizującego. Metody klasy Console służą do prezentacji danych, a stałe tekstowe pomagają w budowie estetycznego interfejsu CLI. Program pokazuje również, jak stosować algorytm szukania ekstremum (minimum/maximum) poprzez proste porównanie w pętli. Zrozumienie mechanizmu działania tablic jest bazą do pracy ze wszystkimi bardziej złożonymi kolekcjami w języku C#.
namespace AutoPremium.Inventory
{
class FleetManager
{
static void Main()
{
// Inicjalizacja tablicy cen pojazdów z sufiksem 'm' dla typu decimal
decimal[] cenyPojazdow = { 245000.50m, 312900.00m, 560000.99m, 189500.00m, 425750.40m };
decimal sumaWartosci = 0;
decimal najdrozszy = cenyPojazdow[0];
Console.WriteLine("=== ANALIZA CEN FLOTY AUTO-PREMIUM ===");
foreach (decimal cena in cenyPojazdow)
{
Console.WriteLine($"Pozycja inwentarzowa: {cena:C2}");
sumaWartosci += cena;
// Algorytm wyznaczania maksimum
if (cena > najdrozszy) najdrozszy = cena;
}
Console.WriteLine(new string('-', 40));
Console.WriteLine($"Łączna wartość ekspozycji: {sumaWartosci:C2}");
Console.WriteLine($"Najdroższy model: {najdrozszy:C2}");
}
}
}
Pozycja inwentarzowa: 245 000,50 zł
Pozycja inwentarzowa: 312 900,00 zł
Pozycja inwentarzowa: 560 000,99 zł
Pozycja inwentarzowa: 189 500,00 zł
Pozycja inwentarzowa: 425 750,40 zł
----------------------------------------
Łączna wartość ekspozycji: 1 733 151,89 zł
Najdroższy model: 560 000,99 zł
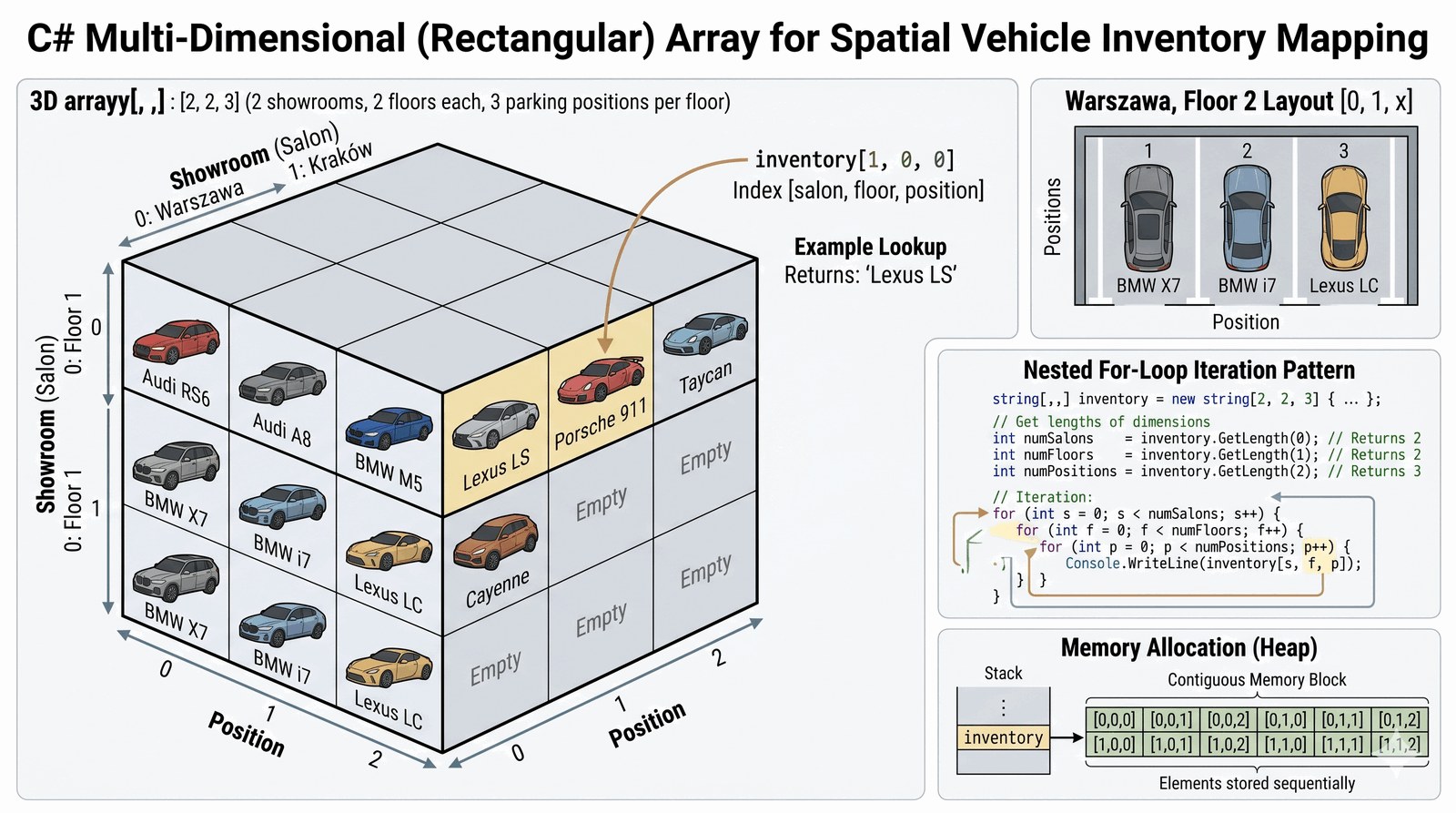
Praktyczne zastosowanie tablic prostokątnych (rectangular arrays) do modelowania struktury przestrzennej oraz agregacji danych w wielu wymiarach jednocześnie.
Globalna sieć salonów Auto-Premium zarządza luksusowymi obiektami wielopoziomowymi w kluczowych metropoliach. Aby zachować najwyższy standard obsługi i pełną kontrolę nad cennymi egzemplarzami, wprowadzono cyfrowy system mapowania przestrzennego floty. Każdy pojazd w systemie jest precyzyjnie przypisany do konkretnego salonu (wymiar 1), piętra (wymiar 2) oraz dedykowanego stanowiska postojowego (wymiar 3). Jako inżynier oprogramowania musisz stworzyć prototyp bazy danych opartej na tablicy trójwymiarowej, która będzie przechowywać kody identyfikacyjne pojazdów dostępnych od ręki. System musi umożliwiać szybką lokalizację konkretnego modelu oraz prezentację obłożenia wybranego piętra w formie czytelnej macierzy (reprezentacja 2D). Takie podejście optymalizuje proces logistyczny i pozwala doradcom na błyskawiczne zaprowadzenie klienta do wymarzonego auta. Dodatkowo, system ma za zadanie zliczać całkowitą liczbę aut dostępnych w danym obiekcie, co ułatwia zarządzanie dostawami. Praca z wieloma wymiarami imituje realne bazy danych stosowane w magazynach wysokiego składowania. Budujesz tutaj inteligentny kompas inwentaryzacyjny, który staje się sercem logistyki Auto-Premium. Każdy błąd w indeksowaniu mógłby skutkować zagubieniem luksusowego pojazdu w ogromnej strukturze salonu. Ten moduł uczy precyzji w zarządzaniu złożonymi zbiorami danych przestrzennych.
Tablica wielowymiarowa (prostokątna) w C# charakteryzuje się tym, że każdy jej wymiar posiada stałą, zdefiniowaną przy inicjalizacji długość. W kodzie deklarujemy ją za pomocą przecinków wewnątrz nawiasów kwadratowych, np. string[,,] dla trzech wymiarów. Taka struktura jest alokowana jako pojedynczy, spójny blok pamięci, co sprawia, że jest bardziej wydajna w dostępie niż tablice tablic (jagged), ze względu na lepszą lokalność danych w pamięci podręcznej procesora (Cache). Inicjalizacja odbywa się poprzez zagnieżdżone nawiasy klamrowe, co wizualnie odzwierciedla hierarchię danych: obiekt -> poziom -> miejsce. Dostęp do konkretnej wartości wymaga podania kompletu indeksów, np. tab[0, 1, 2]. Do iteracji wykorzystujemy zagnieżdżone pętle for, gdzie każda pętla odpowiada za inny wymiar (wymiar zewnętrzny, środkowy i wewnętrzny). Właściwość GetLength(dimension) pozwala na dynamiczne pobranie rozmiaru każdego z wymiarów, co czyni kod odpornym na zmiany wielkości salonów. Do wizualizacji danych 2D (piętro salonu) stosujemy pętle zagnieżdżone, drukując elementy wierszami za pomocą Console.Write(). Typ string jest tu idealny do przechowywania krótkich identyfikatorów modeli. Zrozumienie, jak rzutować trójwymiarową rzeczywistość na strukturę danych w pamięci komputera, jest kluczowe dla każdego dewelopera systemów logistycznych. Pamiętaj, że przekroczenie dowolnego z indeksów natychmiast przerywa działanie programu, dlatego kontrola granic pętli jest tu priorytetem.
class ShowroomMap
{
static void Main()
{
// Deklaracja tablicy 3D: [2 salony, 2 piętra, 3 stanowiska]
string[,,] flota = new string[2, 2, 3]
{
{ // Salon Warszawa
{ "Audi RS6", "Audi A8", "Puste" },
{ "BMW M5", "BMW X7", "BMW i7" }
},
{ // Salon Kraków
{ "Lexus LS", "Puste", "Lexus LC" },
{ "Porsche 911", "Taycan", "Cayenne" }
}
};
Console.WriteLine("=== MAPOWANIE PRZESTRZENNE AUTO-PREMIUM ===");
Console.WriteLine("Wizualizacja Salonu 1 (Warszawa), Piętro 2 (Indeks 1):\n");
// Iteracja po wymiarze stanowisk dla konkretnego salonu i piętra
for (int pos = 0; pos < flota.GetLength(2); pos++)
{
string autoInfo = flota[0, 1, pos];
Console.Write($"[ Stanowisko {pos+1}: {autoInfo,-12} ] ");
}
// Szybkie sprawdzenie konkretnej lokalizacji w Krakowie
Console.WriteLine("\n\nLokalizacja modułowa: Salon 2, Piętro 1, Stanowisko 1");
Console.WriteLine($"Model: {flota[1, 0, 0]}");
Console.WriteLine(new string('=', 50));
}
}
Wizualizacja Salonu 1 (Warszawa), Piętro 2 (Indeks 1):
[ Stanowisko 1: BMW M5 ] [ Stanowisko 2: BMW X7 ] [ Stanowisko 3: BMW i7 ]
Lokalizacja modułowa: Salon 2, Piętro 1, Stanowisko 1
Model: Lexus LS
==================================================
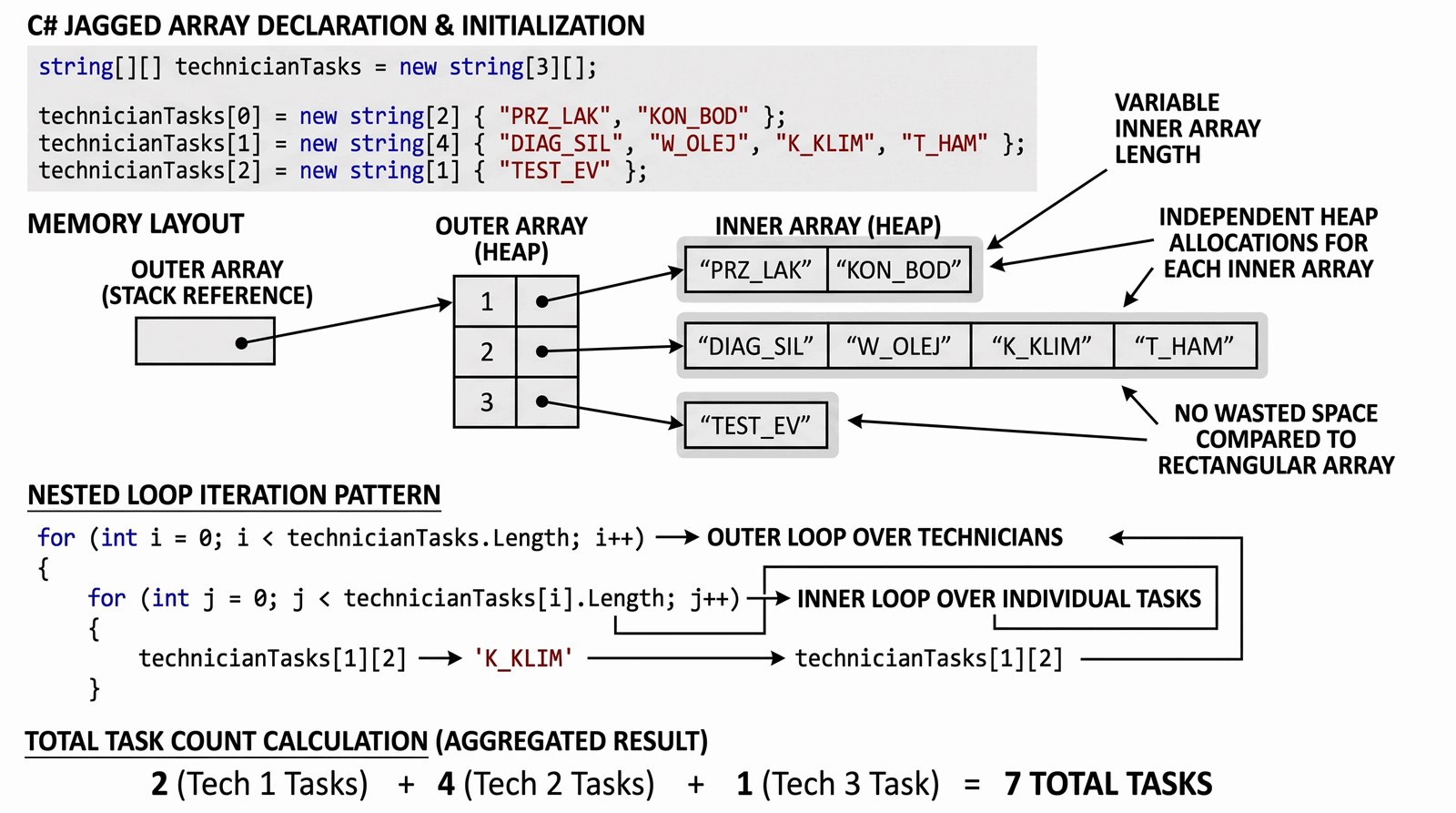
Poznanie elastyczności tablic nieregularnych (jagged arrays) w modelowaniu nierównomiernych zbiorów danych oraz optymalizacja wykorzystania pamięci.
Dział serwisu Auto-Premium zatrudnia zespół specjalistów, z których każdy posiada unikalny zakres kompetencji i indywidualny model zatrudnienia. Wiąże się to z różną liczbą zadań serwisowych przypisanych na dany dzień roboczy dla każdego mechanika. System planowania operacyjnego musi być na tyle elastyczny, by poprawnie obsłużyć sytuację, gdzie jeden pracownik (np. ekspert od napędów hybrydowych) ma zaplanowane tylko dwie długotrwałe diagnostyki, podczas gdy inny (technik serwisu ekspresowego) realizuje siedem szybkich wymian płynów eksploatacyjnych. Twoim zadaniem jest stworzenie struktury opartej na tablicy nieregularnej, która będzie rzetelnie przechowywać kody zleceń dla każdego technika z osobna. Program ma za zadanie umożliwić wyświetlenie pełnego zestawienia prac dla wybranego pracownika oraz policzyć sumaryczną liczbę wszystkich zleceń aktualnie realizowanych w całym warsztacie. Taka optymalizacja jest kluczowa dla precyzyjnego zarządzania czasem w segmencie luksusowym, gdzie terminowość jest priorytetem. Uczysz się tutaj, jak efektywnie zarządzać zasobami systemowymi w sytuacjach, gdy struktura danych nie jest symetryczna i wymaga dynamicznej alokacji wierszy. Każde zadanie to oddzielny wpis, który buduje historię serwisową pojazdu klienta. Ten moduł to fundament dla zaawansowanych algorytmów kolejkowania prac w salonie.
Tablica nieregularna (jagged array) w języku C# to specyficzna konstrukcja "tablicy tablic". Oznacza to, że każdy element tablicy głównej nie jest bezpośrednią wartością, lecz referencją do innej, niezależnej tablicy, która może posiadać swoją własną, unikalną długość. Deklaracja string[][] tworzy hierarchię: najpierw inicjalizujemy tablicę "pojemnik" (określając liczbę mechaników), a następnie każdą pod-tablicę z osobna, przydzielając jej konkretny rozmiar potrzebny na zadania. Jest to podejście znacznie bardziej elastyczne od tablic wielowymiarowych w sytuacjach niejednorodnych danych, choć wiąże się z większym obciążeniem dla modelu Garbage Collection ze względu na rozproszoną alokację mniejszych obiektów na stercie (Heap). Dostęp do konkretnej informacji odbywa się za pomocą podwójnego, oddzielnego nawiasu kwadratowego, np. harmonogram[indeksPracownika][indeksZadania]. Właściwość Length wywołana na tablicy głównej zwraca liczbę wierszy (pracowników), natomiast harmonogram[i].Length pozwala sprawdzić liczbę kolumn (zadań) dla konkretnego wiersza. Do przetwarzania takich struktur najlepiej nadaje się pętla zagnieżdżona (outer-inner loop pattern), która systematycznie przechodzi przez każdy poziom referencji. Program demonstruje, jak przy użyciu minimalnych nakładów pamięci stworzyć precyzyjny obraz obciążenia pracą rozproszonego zespołu technicznego.
class ServiceScheduler
{
static void Main()
{
// Inicjalizacja tablicy nieregularnej (jagged array)
string[][] harmonogram = new string[3][];
// Definiowanie zadań dla poszczególnych techników
harmonogram[0] = new string[] { "PRZ_LAK", "KON_BOD" }; // 2 zadania
harmonogram[1] = new string[] { "DIAG_SIL", "W_OLEJ", "K_KLIM", "T_HAM" }; // 4 zadania
harmonogram[2] = new string[] { "TEST_EV" }; // 1 zadanie
Console.WriteLine("=== HARMONOGRAM SERWISOWY AUTO-PREMIUM ===");
int lacznaLiczbaZadan = 0;
for (int i = 0; i < harmonogram.Length; i++)
{
string formaZadan = harmonogram[i].Length == 1 ? "zadanie" : (harmonogram[i].Length % 10 >= 2 && harmonogram[i].Length % 10 <= 4 && (harmonogram[i].Length % 100 < 10 || harmonogram[i].Length % 100 >= 20)) ? "zadania" : "zadań";
Console.WriteLine($"Technik ID: {i + 1} ({harmonogram[i].Length} {formaZadan})");
for (int j = 0; j < harmonogram[i].Length; j++)
{
Console.WriteLine($" -> Zlecenie: {harmonogram[i][j]}");
lacznaLiczbaZadan++;
}
}
Console.WriteLine(new string('=', 42));
Console.WriteLine($"Suma zleceń w toku: {lacznaLiczbaZadan}");
}
}
Technik ID: 1 (2 zadania)
-> Zlecenie: PRZ_LAK
-> Zlecenie: KON_BOD
Technik ID: 2 (4 zadania)
-> Zlecenie: DIAG_SIL
-> Zlecenie: W_OLEJ
-> Zlecenie: K_KLIM
-> Zlecenie: T_HAM
Technik ID: 3 (1 zadanie)
-> Zlecenie: TEST_EV
==========================================
Suma zleceń w toku: 7
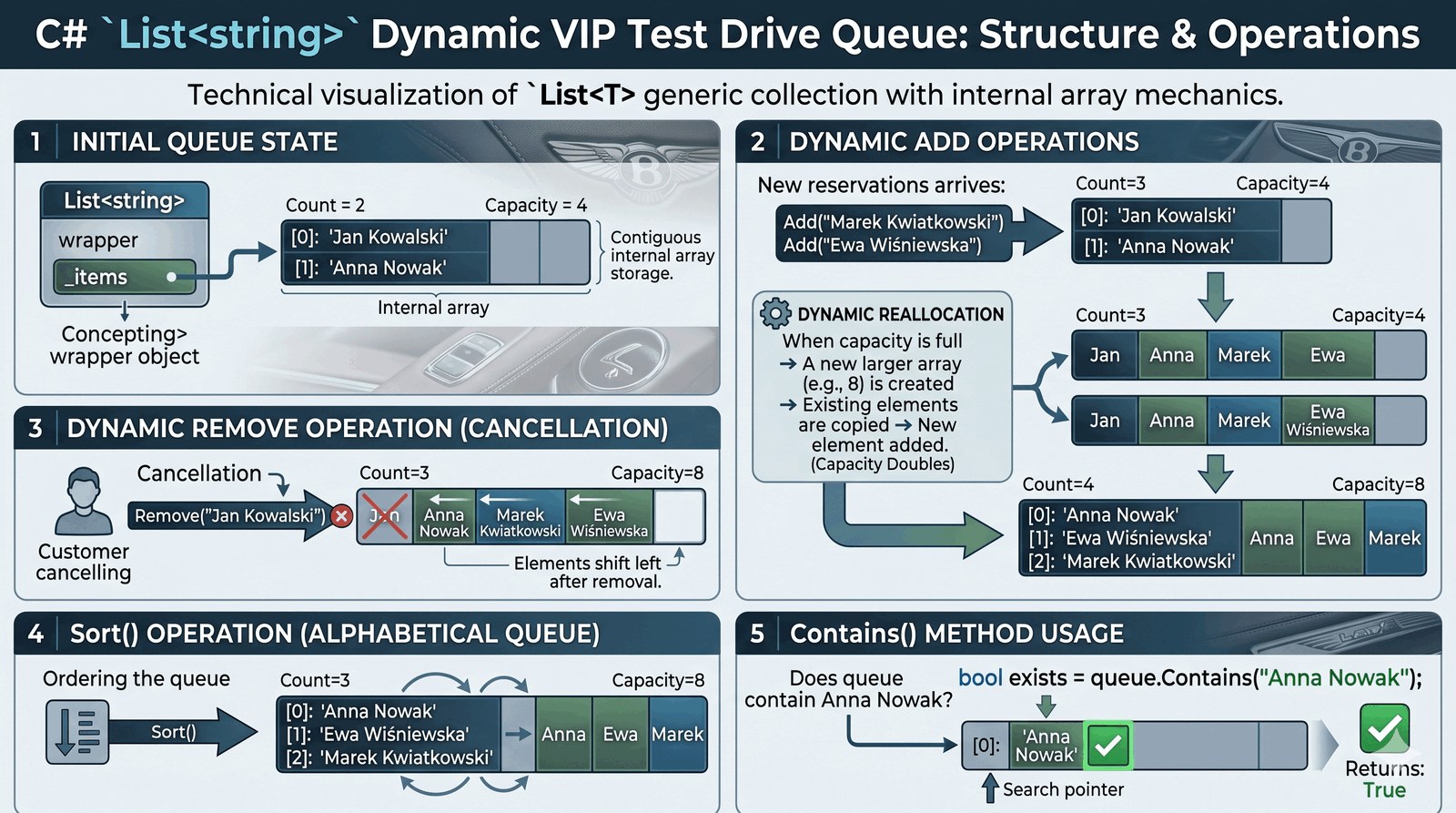
Implementacja dynamicznego zarządzania zbiorami danych przy użyciu generycznej kolekcji List oraz poznanie metod manipulacji elementami w czasie wykonania programu.
Salon Auto-Premium wdrożył nową, ekskluzywną usługę "Priority Concierge", która umożliwia najważniejszym klientom (segment VIP) dynamiczne zapisywanie się na listę oczekujących na jazdę próbną najnowszym, limitowanym modelem sportowym. W przeciwieństwie do statycznych tablic, lista ta podlega ciągłym zmianom w czasie rzeczywistym – nowi goście dopisują się do kolejki, inni z powodu nagłych spotkań rezygnują, a jeszcze inni są sukcesywnie obsługiwani przez doradców i usuwani z systemu. Twoim zadaniem jest stworzenie silnika zarządzającego tą listą, opartego na elastycznej kolekcji generycznej List. Program musi umożliwiać płynne dodawanie nowych nazwisk do bazy, usuwanie konkretnego klienta na podstawie jego danych osobowych, weryfikację czy dana osoba znajduje się już w kolejce oraz końcowe, alfabetyczne sortowanie listy dla potrzeb porannej odprawy personelu. Wykorzystanie dynamicznej alokacji pamięci sprawia, że system jest w stanie obsłużyć dowolną liczbę zgłoszeń bez ryzyka przepełnienia bufora. To zadanie wprowadza Cię w świat najbardziej uniwersalnej struktury danych w ekosystemie .NET. Budujesz tutaj inteligentnego zarządcę kolejki, który bezpośrednio wpływa na doświadczenie luksusu płynące z kontaktu z marką. Każda operacja na liście musi być precyzyjna, aby nie pominąć żadnego z gości salonu.
Generyczna kolekcja List to potężny odpowiednik tablicy, który jednak samodzielnie zarządza rozmiarem zajmowanej pamięci. Wewnątrz klasy listy nadal znajduje się standardowa tablica, ale cały mechanizm jej powiększania jest ukryty przed programistą. W momencie, gdy dodawany element przekracza bieżącą pojemność (Capacity), lista automatycznie tworzy nową, dwukrotnie większą tablicę pomocniczą i kopiuje do niej istniejące dane – jest to tzw. mechanizm dynamicznej reallokacji. Metoda Add() wstawia nową referencję na koniec zbioru, podczas gdy Remove() wyszukuje element i po jego usunięciu przesuwa pozostałe elementy, by zlikwidować lukę (jest to ważne dla spójności indeksowania). Właściwość Count dostarcza informacji o rzeczywistej liczbie przechowywanych obiektów, co odróżnia ją od właściwości Length w tablicach statycznych. Dodatkowo, funkcja Contains() implementuje algorytm przeszukiwania liniowego, zwracając wartość logiczną o obecności elementu. Wywołanie Sort() porządkuje listę z wykorzystaniem wydajnego algorytmu IntroSort (hybryda QuickSort i HeapSort), zapewniając optymalny czas pracy O(n log n). Dzięki generyczności (InvalidCastException w czasie działania aplikacji.
using System.Collections.Generic; // Wymagane dla List<T>
class PriorityConcierge
{
static void Main()
{
// Inicjalizacja luksusowej listy VIPów
List<string> listaGosci = new List<string> { "Jan Kowalski", "Anna Nowak" };
// Dynamiczne dodawanie nowych klientów
listaGosci.Add("Marek Kwiatkowski");
listaGosci.Add("Ewa Wiśniewska");
Console.WriteLine("=== SYSTEM CONCIERGE AUTO-PREMIUM ===");
Console.WriteLine($"Aktualna liczba gości w kolejce: {listaGosci.Count}");
// Symulacja rezygnacji klienta
Console.WriteLine("[SYSTEM] Usuwanie klienta: Jan Kowalski (rezygnacja)");
listaGosci.Remove("Jan Kowalski");
// Sortowanie listy przed wydrukiem raportu
listaGosci.Sort();
Console.WriteLine("\nZatwierdzona lista priorytetowa (Alfabetycznie):");
int numeracja = 1;
foreach (string gosc in listaGosci)
{
Console.WriteLine($"{numeracja++}. {gosc}");
}
// Sprawdzenie dostępności konkretnej osoby
bool czyJest = listaGosci.Contains("Anna Nowak");
Console.WriteLine($"\nStatus: Anna Nowak oczekuje = {czyJest}");
}
}
Aktualna liczba gości w kolejce: 4
[SYSTEM] Usuwanie klienta: Jan Kowalski (rezygnacja)
Zatwierdzona lista priorytetowa (Alfabetycznie):
1. Anna Nowak
2. Ewa Wiśniewska
3. Marek Kwiatkowski
Status: Anna Nowak oczekuje = True
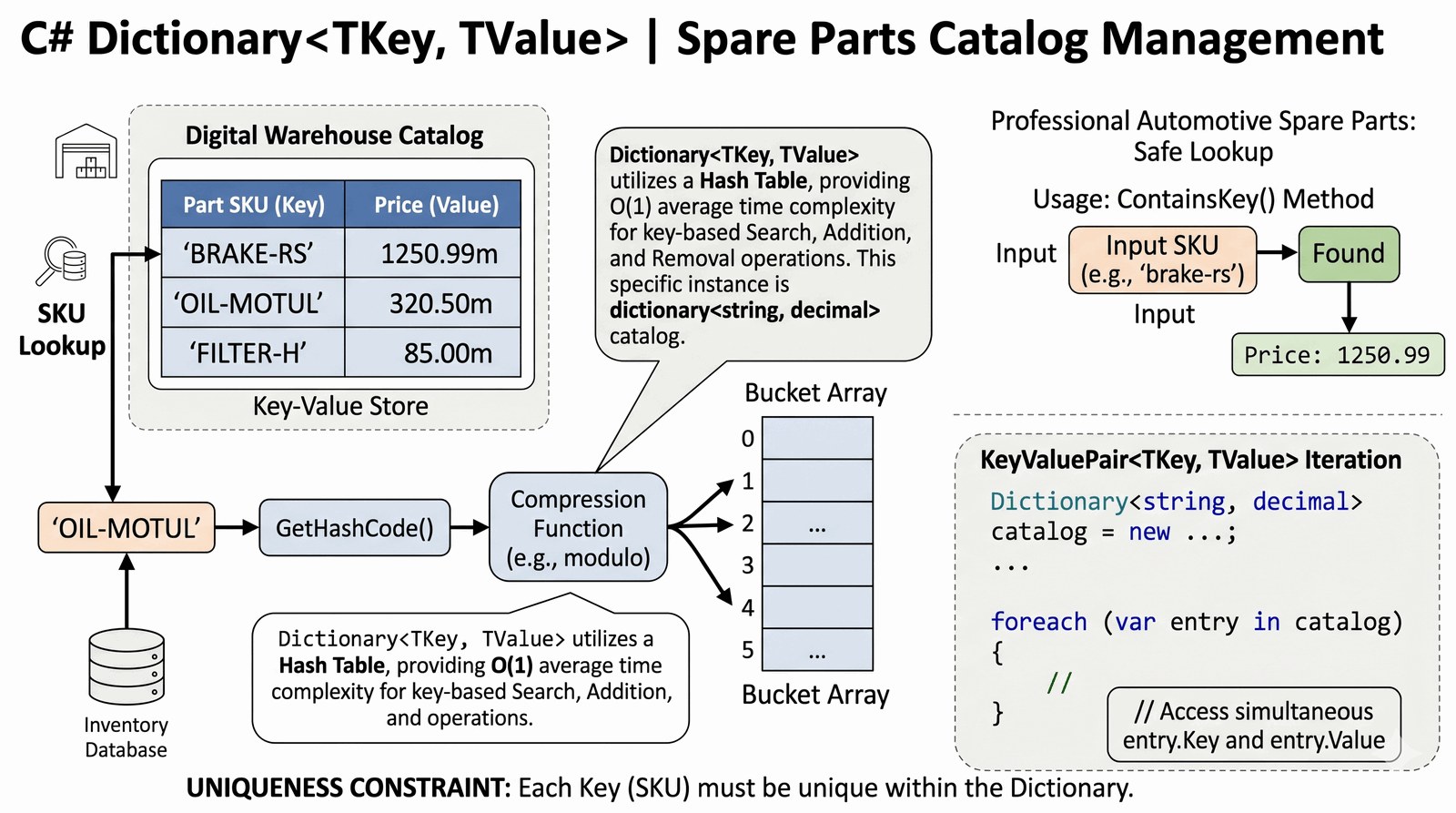
Zrozumienie struktury asocjacyjnej klucz-wartość oraz optymalizacja wyszukiwania danych przy użyciu kolekcji Dictionary (Hash Table).
Magazyn centralny grupy Auto-Premium zarządza dziesiątkami tysięcy unikalnych podzespołów i części zamiennych, z których każda posiada swój unikalny kod alfanumeryczny SKU (np. "TRB-99-AUD"). W dynamicznym środowisku serwisowym, gdzie czas naprawy przekłada się bezpośrednio na zadowolenie klienta, tradycyjne przeszukiwanie list w celu znalezienia ceny konkretnej części byłoby krytycznie nieefektywne. Twoim zadaniem jest stworzenie cyfrowego katalogu opartego na słowniku, gdzie kluczem jest unikatowy kod SKU, a wartością przypisana do niego cena rynkowa. Program musi pozwalać na błyskawiczne sprawdzenie kosztu na podstawie wpisanego kodu, dodawanie nowych pozycji do bazy oraz weryfikację dostępności towaru w systemie. Taka struktura gwarantuje, że czas operacji wyszukiwania pozostaje niemal stały, niezależnie od tego, czy w katalogu znajduje się dziesięć, czy milion rekordów. Budujesz tutaj fundament nowoczesnego systemu ERP dla działu logistyki i serwisu, gdzie precyzja spotyka się z ekstremalną wydajnością dostępu do informacji. Każda prawidłowo zmapowana para klucz-wartość chroni salon przed stratami wynikającymi z nieaktualnych cenników. To zadanie uczy Cię myślenia o danych w kategoriach asocjacji i unikalności.
Słownik (Dictionary) w języku C# to kolekcja generyczna oparta na zaawansowanym modelu tablicy mieszającej (Hash Table). Proces zapisu polega na tym, że każdy klucz jest poddawany działaniu funkcji skrótu (GetHashCode), co pozwala na natychmiastowe wyliczenie indeksu w pamięci, pod którym znajduje się powiązana z nim wartość. Zapewnia to teoretyczną złożoność obliczeniową O(1) dla najważniejszych operacji: wyszukiwania, wstawiania i usuwania. Klucze w obrębie jednego słownika muszą być bezwzględnie unikalne – próba dodania klucza już istniejącego spowoduje rzucenie wyjątku ArgumentException. Do bezpiecznej pracy z danymi, których obecności nie jesteśmy pewni, zaleca się stosowanie metody ContainsKey() lub metody TryGetValue(), która zwraca wynik operacji jako parametr wyjściowy (out). Iteracja po słowniku zwraca kolekcję struktur KeyValuePair, co pozwala na jednoczesny dostęp do obu składowych pary. Zastosowanie typu decimal dla wartości cenowych zapewnia stabilność finansową obliczeń. Słowniki są niezwykle optymalne przy mapowaniu identyfikatorów na złożone obiekty, co stanowi kręgosłup większości współczesnych systemów bazodanowych pracujących w pamięci operacyjnej.
using System.Collections.Generic;
class SparePartsCatalog
{
static void Main()
{
// Inicjalizacja słownika: Klucz (SKU) -> Wartość (Cena)
Dictionary<string, decimal> katalogCzesci = new Dictionary<string, decimal>();
// Dodawanie rekordów do bazy magazynowej
katalogCzesci.Add("BRAKE-RS", 1250.99m);
katalogCzesci.Add("OIL-MOTUL", 320.50m);
katalogCzesci.Add("FILTER-H", 85.00m);
Console.WriteLine("=== KATALOG CZĘŚCI ZAMIENNYCH AUTO-PREMIUM ===");
Console.Write("Podaj kod SKU części do wyceny: ");
string szukaneSKU = Console.ReadLine().ToUpper();
// Bezpieczne wyciąganie danych za pomocą ContainsKey
if (katalogCzesci.ContainsKey(szukaneSKU))
{
decimal cena = katalogCzesci[szukaneSKU];
Console.WriteLine($"[WYNIK] Część znaleziona. Cena rynkowa: {cena:C2}");
}
else
{
Console.WriteLine("[BŁĄD] Podany kod SKU nie istnieje w bazie centralnej.");
}
Console.WriteLine("\nPełne zestawienie dostępnych kodów:");
foreach (var wpis in katalogCzesci) // wpis jest typu KeyValuePair
{
Console.WriteLine($"- SKU: {wpis.Key,-12} | Cena Netto: {wpis.Value,10:C2}");
}
}
}
Podaj kod SKU części do wyceny: brake-rs
[WYNIK] Część znaleziona. Cena rynkowa: 1 250,99 zł
Pełne zestawienie dostępnych kodów:
- SKU: BRAKE-RS | Cena Netto: 1 250,99 zł
- SKU: OIL-MOTUL | Cena Netto: 320,50 zł
- SKU: FILTER-H | Cena Netto: 85,00 zł
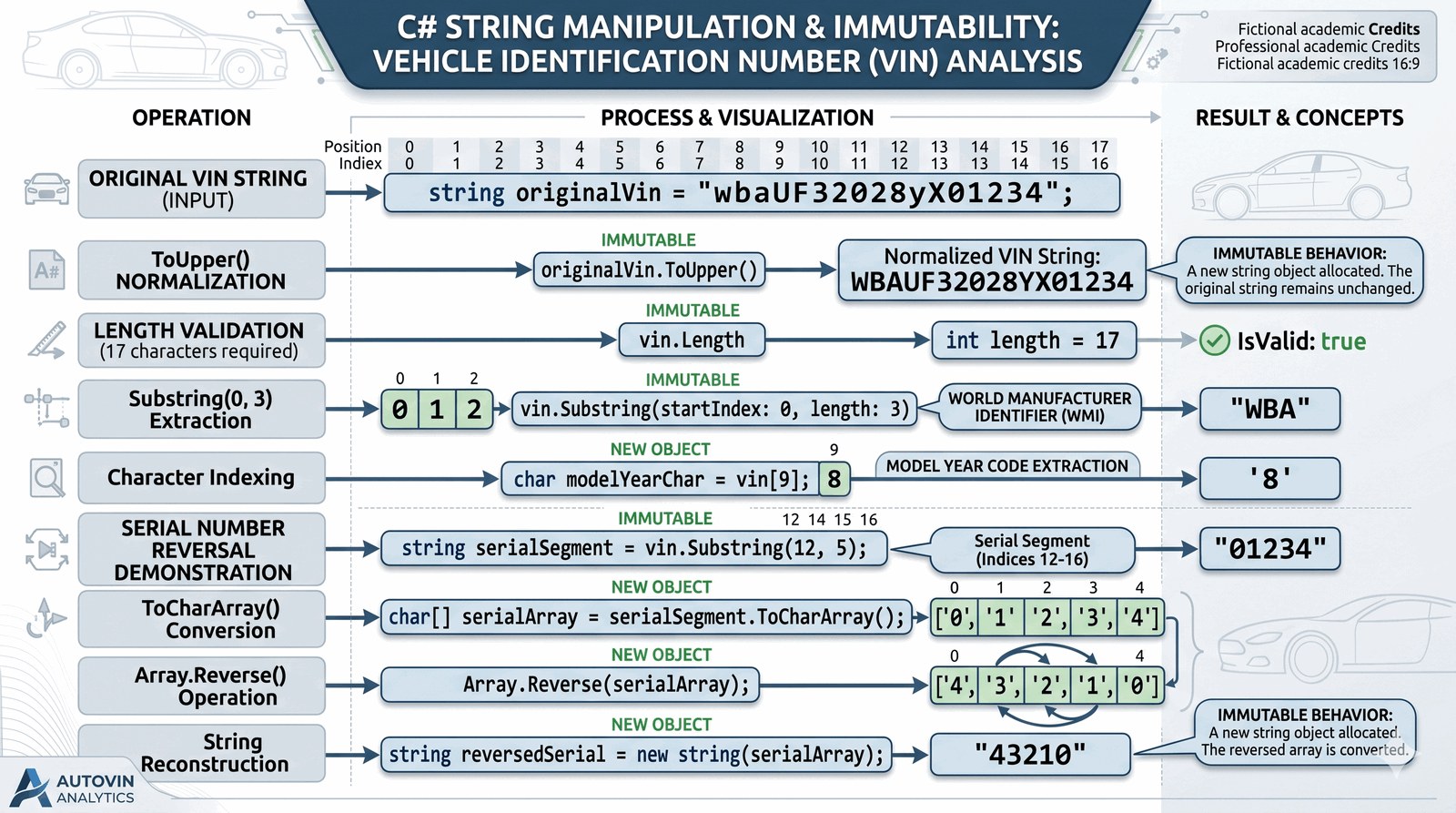
Poznanie zaawansowanych technik manipulacji łańcuchami znaków oraz traktowanie typu string jako tablicy znaków (char array) w celach analitycznych.
Każdy luksusowy pojazd opuszczający fabrykę i trafiający do salonu Auto-Premium posiada unikalny, 17-znakowy numer VIN (Vehicle Identification Number). System zarządzania flotą musi potrafić samodzielnie "rozbić" ten skomplikowany ciąg znaków na czynniki pierwsze, aby błyskawicznie zweryfikować kraj pochodzenia, rok modelowy oraz specyficzne cechy wyposażenia danego egzemplarza. Twoim zadaniem jest stworzenie modułu analitycznego, który przyjmuje numer VIN jako wejście tekstowe, a następnie wykonuje na nim serię operacji weryfikacyjnych i transformacyjnych. Program musi zmienić litery na wielkie dla ujednolicenia bazy, sprawdzić poprawność długości ciągu, wyciągnąć konkretne podciągi (np. kod producenta - pierwsze 3 znaki) oraz poddać analizie pojedyncze znaki przy użyciu indeksowania bezpośredniego. Dodatkowo, system musi potrafić odwrócić segment numeru seryjnego w celach generowania unikalnych kodów serwisowych. Takie przetwarzanie tekstu jest kluczowe przy integracji z międzynarodowymi bazami danych producentów aut. Budujesz tutaj inteligentny skaner tożsamości pojazdu, który stanowi pierwszą linię weryfikacji danych w systemie CRM. Każdy znak w numerze VIN ma swoją wagę, a Twoim celem jest ich poprawne zinterpretowanie.
W języku C# typ string jest w rzeczywistości niemutowalną (immutable) sekwencją znaków Unicode (char). Możemy uzyskać dostęp do każdego znaku z osobna za pomocą operatora indeksowania, np. vin[0], co zachowuje się identycznie jak w przypadku tablicy jednowymiarowej. Bardzo ważną metodą jest Substring(startIndex, length), która pozwala na precyzyjną ekstrakcję fragmentów tekstu bez modyfikowania oryginału. Inne fundamenty pracy z tekstem to ToUpper() (normalizacja wielkości liter), Trim() (usuwanie zbędnych spacji) oraz właściwość Length określająca precyzyjnie liczbę znaków. Metoda ToCharArray() konwertuje łańcuch znaków na mutowalną tablicę char[], co pozwala na wykonanie operacji takich jak odwracanie kolejności za pomocą statycznej metody Array.Reverse(). Należy pamiętać, że ponieważ stringi są niemutowalne, każda operacja transformacji (np. Replace) w rzeczywistości tworzy zupełnie nowy obiekt na stercie (Heap). Zrozumienie tego mechanizmu jest kluczowe dla optymalizacji pamięciowej aplikacji, zwłaszcza przy przetwarzaniu dużych zbiorów danych tekstowych. Program uczy, jak zamienić surowy strumień znaków w strukturalną informację biznesową, gotową do dalszego wykorzystania w systemach klasy luksusowej.
class VinAnalyzer
{
static void Main()
{
Console.WriteLine("=== MODUŁ ANALIZY VIN AUTO-PREMIUM ===");
Console.Write("Wprowadź numer VIN pojazdu: ");
string rawVin = Console.ReadLine().Trim().ToUpper();
if (rawVin.Length != 17)
{
Console.WriteLine("[!] BŁĄD: Numer VIN musi posiadać dokładnie 17 znaków.");
return;
}
// Ekstrakcja sub-stringów (segmentów)
string wmi = rawVin.Substring(0, 3); // World Manufacturer Identifier
char rokKod = rawVin[9]; // 10-ty znak to rok modelowy
string numerSeryjny = rawVin.Substring(12);
// Operacja na tablicy znaków - odwrócenie numeru seryjnego
char[] serialChars = numerSeryjny.ToCharArray();
Array.Reverse(serialChars);
string reversedSerial = new string(serialChars);
Console.WriteLine("\n[RAPORT DEKODOWANIA]");
Console.WriteLine($"1. Kod producenta (WMI): {wmi}");
Console.WriteLine($"2. Identyfikator roku: {rokKod}");
Console.WriteLine($"3. Numer seryjny: {numerSeryjny}");
Console.WriteLine($"4. Kod zabezpieczający: {reversedSerial}");
}
}
Wprowadź numer VIN pojazdu: wba12345678901234
[RAPORT DEKODOWANIA]
1. Kod producenta (WMI): WBA
2. Identyfikator roku: 8
3. Numer seryjny: 01234
4. Kod zabezpieczający: 43210
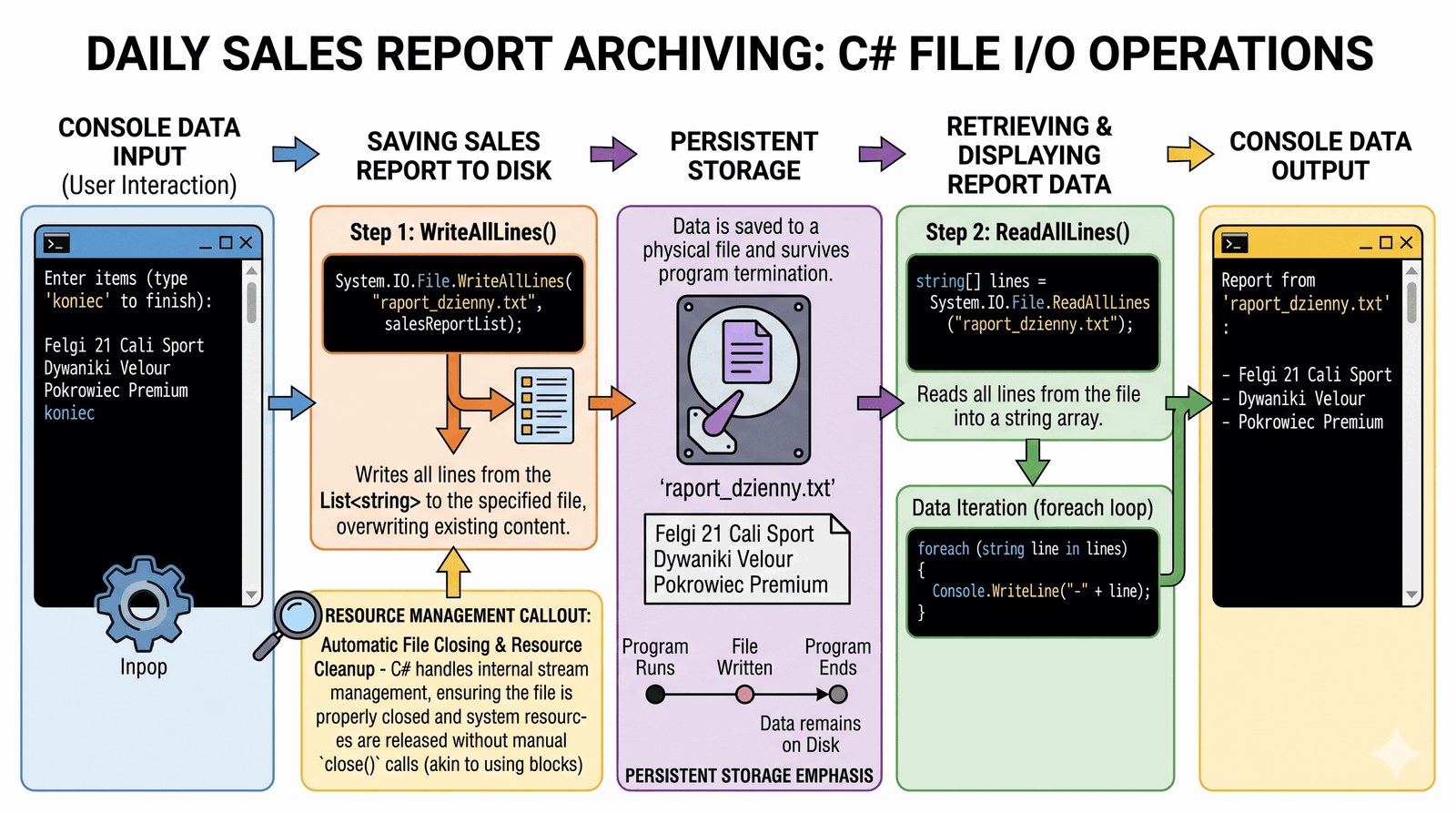
Opanowanie podstaw operacji wejścia/wyjścia (File I/O) na plikach tekstowych przy użyciu klasy File w celu trwałego utrwalania danych biznesowych.
Zarząd grupy Auto-Premium wymaga, aby każde zestawienie sprzedaży akcesoriów z końca dnia było bezwzględnie zapisywane w formie raportu tekstowego na zabezpieczonym dysku serwera. Dane te stanowią fundamentem historii transakcji i są niezbędne dla działu księgowości przy comiesięcznych audytach. Twoim zadaniem jest stworzenie modułu archiwizującego, który pobiera od pracownika salonu nazwy sprzedanych dziś produktów, zapisuje je do pliku o nazwie raport_dzienny.txt (zachowując strukturę listy), a następnie – w celu automatycznej weryfikacji poprawności zapisu – odczytuje ten plik i wyświetla jego pełną zawartość w oknie konsoli sterującej. System musi gwarantować, że dane nie zostaną utracone po wyłączeniu programu lub awarii zasilania terminala. Praca z systemem plików jest krytycznym elementem budowy profesjonalnych aplikacji typu enterprise, które muszą trwale utrwalać swój stan i komunikować się z innymi modułami korporacyjnymi. Budujesz tutaj cyfrowe archiwum, które wyparło tradycyjne, papierowe rejestry sprzedaży. Każdy wiersz w pliku to potwierdzenie udanego kontaktu handlowego z klientem klasy Premium.
Statyczna klasa System.IO.File w środowisku .NET dostarcza zestawu potężnych metod do błyskawicznego zarządzania plikami bez konieczności ręcznego operowania na strumieniach (Streams). Metoda WriteAllLines(path, collection) to niezwykle wygodne narzędzie, które przyjmuje ścieżkę do pliku oraz kolekcję (np. List lub tablicę), a następnie tworzy plik i zapisuje każdy element kolekcji w nowej linii, automatycznie dbając o zamknięcie pliku i zwolnienie zasobów systemowych. Z kolei metoda ReadAllLines(path) działa w drugą stronę – odczytuje całą zawartość pliku i zwraca ją jako tablicę ciągów znaków, co pozwala na łatwą iterację i prezentację danych. Należy zwrócić uwagę, że WriteAllLines domyślnie nadpisuje istniejący plik (jeśli chcemy dopisywać dane, używamy AppendAllLines). Podczas operacji na systemie plików należy zawsze brać pod uwagę potencjalne problemy z uprawnieniami dostępu (I/O Errors) oraz fizyczny brak pliku w lokalizacji. Trwała archiwizacja danych to podstawowy filar bezpieczeństwa każdego systemu informatycznego pracującego w sektorze finansowym i handlowym.
using System.IO; // Niezbędne dla operacji na plikach
using System.Collections.Generic;
class DailyReportManager
{
static void Main()
{
string sciezka = "raport_dzienny.txt";
List<string> sprzedaz = new List<string>();
Console.WriteLine("=== SYSTEM ARCHIWIZACJI AUTO-PREMIUM ===");
Console.WriteLine("Wprowadź listę sprzedanych akcesoriów (wpisz 'koniec' aby zapisać):");
while (true)
{
Console.Write("> ");
string wpis = Console.ReadLine();
if (wpis.ToLower() == "koniec") break;
sprzedaz.Add(wpis);
}
// Zapisywanie danych do pliku tekstowego
File.WriteAllLines(sciezka, sprzedaz);
Console.WriteLine("\n[SYSTEM] Raport został trwale zapisany na dysku.");
// Odczytywanie danych z pliku w celu weryfikacji
Console.WriteLine("\nTreść odczytana z pliku tekstowego:");
string[] zawartosc = File.ReadAllLines(sciezka);
foreach (string linia in zawartosc)
{
Console.WriteLine($" - {linia}");
}
}
}
Wprowadź listę sprzedanych akcesoriów (wpisz 'koniec' aby zapisać):
> Felgi 21 Cali Sport
> Dywaniki Velour
> Pokrowiec Premium
> koniec
[SYSTEM] Raport został trwale zapisany na dysku.
Treść odczytana z pliku tekstowego:
- Felgi 21 Cali Sport
- Dywaniki Velour
- Pokrowiec Premium
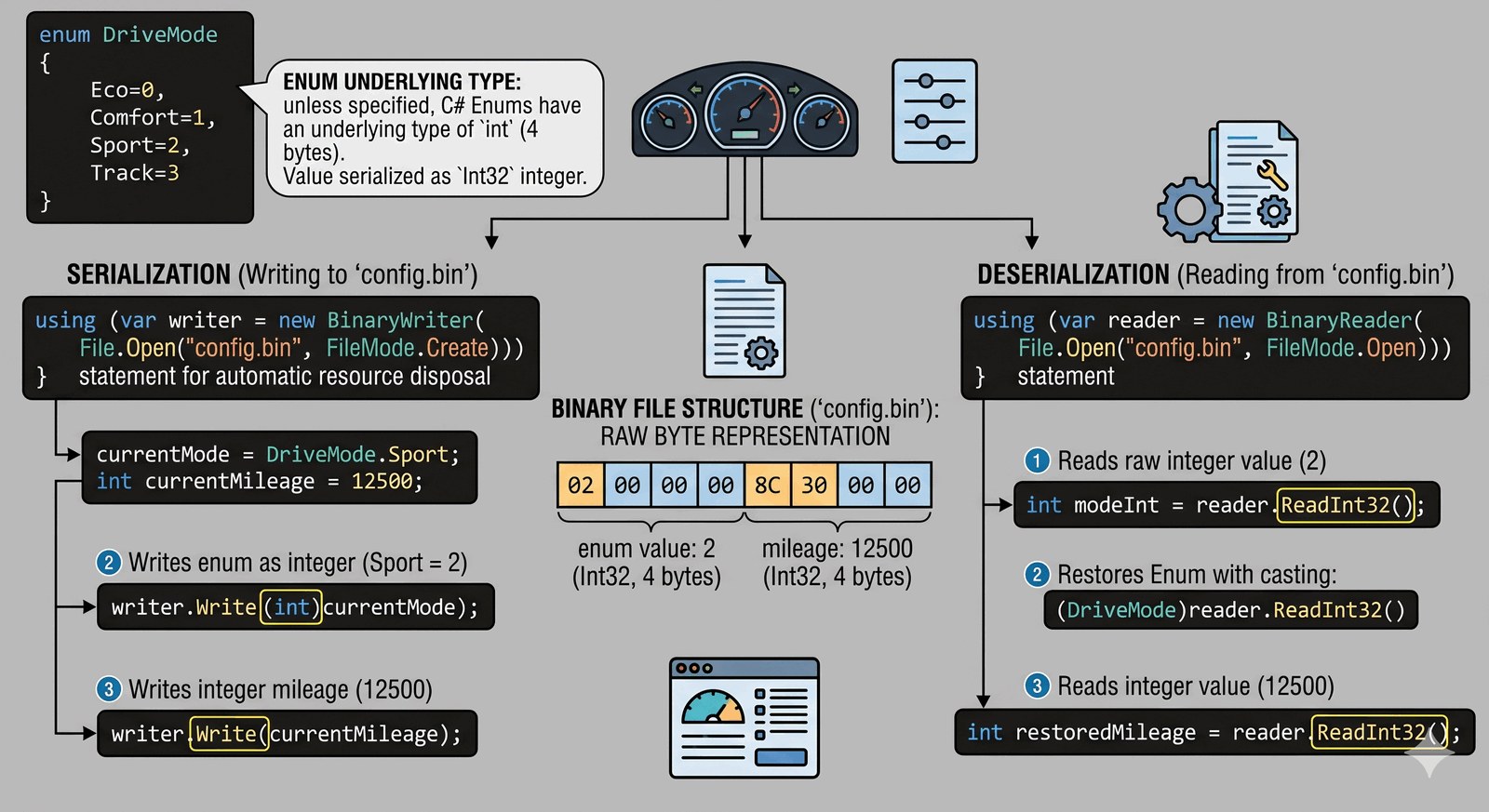
Praktyczne zastosowanie typów wyliczeniowych (Enum) do kategoryzacji stanów aplikacji oraz zapisywanie i odczytywanie danych w formacie binarnym dla maksymalnej wydajności.
Systemy pokładowe najnowszych modeli Auto-Premium przechowują złożone ustawienia personalizacji (np. tryb pracy zawieszenia, mapę wtrysku czy kolorystykę kokpitu) w kompaktowych plikach binarnych. Takie rozwiązanie gwarantuje błyskawiczny start systemów pokładowych oraz chroni parametry techniczne przed nieautoryzowaną edycją w prostych edytorach tekstu. Twoim zadaniem jest stworzenie modułu konfiguracyjnego, który wykorzystuje typ wyliczeniowy DriveMode (Eco, Comfort, Sport, Track) do zarządzania profilami jazdy. Wybrany przez kierowcę profil oraz zapisany stan licznika muszą zostać trwale zserializowane do pliku binarnego o nazwie config.bin. Program musi następnie potrafić odczytać ten plik i zinterpretować surowe dane z powrotem na czytelne dla człowieka nazwy stanów z enuma. Ten proces "zamrażania" stanu systemu w strumieniu bajtów jest fundamentem zaawansowanej inżynierii systemów wbudowanych. Budujesz tutaj inteligentny kontroler profilu kierowcy, który dba o to, by każda podróż zaczynała się od preferowanych ustawień. Precyzja w operowaniu na bajtach jest tu równie ważna, co płynność zmiany biegów w luksusowym sportowym aucie.
Typ wyliczeniowy (enum) w języku C# pozwala na stworzenie zestawu nazwanych stałych liczbowych, co dramatycznie wpływa na czystość kodu i eliminuje błędy typu "magic numbers". Pod spodem enum jest zazwyczaj reprezentowany jako typ int, co czyni go bardzo wydajnym w transmisji. Z kolei praca z plikami binarnymi odbywa się przy użyciu klas BinaryWriter oraz BinaryReader. W przeciwieństwie do plików tekstowych, które wymuszają formatowanie każdej liczby na znaki, zapis binarny przesyła dane w ich surowej postaci bajtowej (np. każda liczba int to dokładnie 4 bajty). Zapewnia to oszczędność miejsca na dysku i przyspiesza proces odczytu. Najważniejszą zasadą przy pracy z BinaryReader jest zachowanie ścisłej, identycznej kolejności odczytu, w jakiej dane zostały zapisane – system plików binarnych nie posiada separatorów, więc to programista musi wiedzieć, kiedy kończy się jedna dana, a zaczyna kolejna. Jawne rzutowanie (casting), np. (DriveMode)readInt, pozwala na elegancki powrót z surowej liczby do logicznego stanu aplikacji. Opanowanie zapisu binarnego to wejście w świat wysokowydajnego przetwarzania danych.
using System.IO; // Wymagane dla BinaryWriter/Reader
namespace AutoPremium.Settings
{
// Definicja typu wyliczeniowego dla trybów jazdy
enum DriveMode { Eco, Comfort, Sport, Track }
class ConfigManager
{
static void Main()
{
string fileName = "config.bin";
DriveMode wybranyTryb = DriveMode.Sport;
int przebieg = 12500;
// Zapis binarny ustawień
using (BinaryWriter writer = new BinaryWriter(File.Open(fileName, FileMode.Create)))
{
writer.Write((int)wybranyTryb); // Rzutowanie enuma na int przed zapisem
writer.Write(przebieg);
}
Console.WriteLine("=== MODUŁ SERIALIZACJI KONFIGURACJI ===");
Console.WriteLine("[OK] Parametry zapisane w formacie binarnym.");
// Odczyt binarny ustawień
using (BinaryReader reader = new BinaryReader(File.Open(fileName, FileMode.Open)))
{
DriveMode wczytanyTryb = (DriveMode)reader.ReadInt32();
int wczytanyPrzebieg = reader.ReadInt32();
Console.WriteLine("\nOdczytana konfiguracja z pliku:");
Console.WriteLine($"-> Aktywny Tryb Jazdy: {wczytanyTryb}");
Console.WriteLine($"-> Zapisany Przebieg: {wczytanyPrzebieg} km");
}
}
}
}
[OK] Parametry zapisane w formacie binarnym.
Odczytana konfiguracja z pliku:
-> Aktywny Tryb Jazdy: Sport
-> Zapisany Przebieg: 12500 km
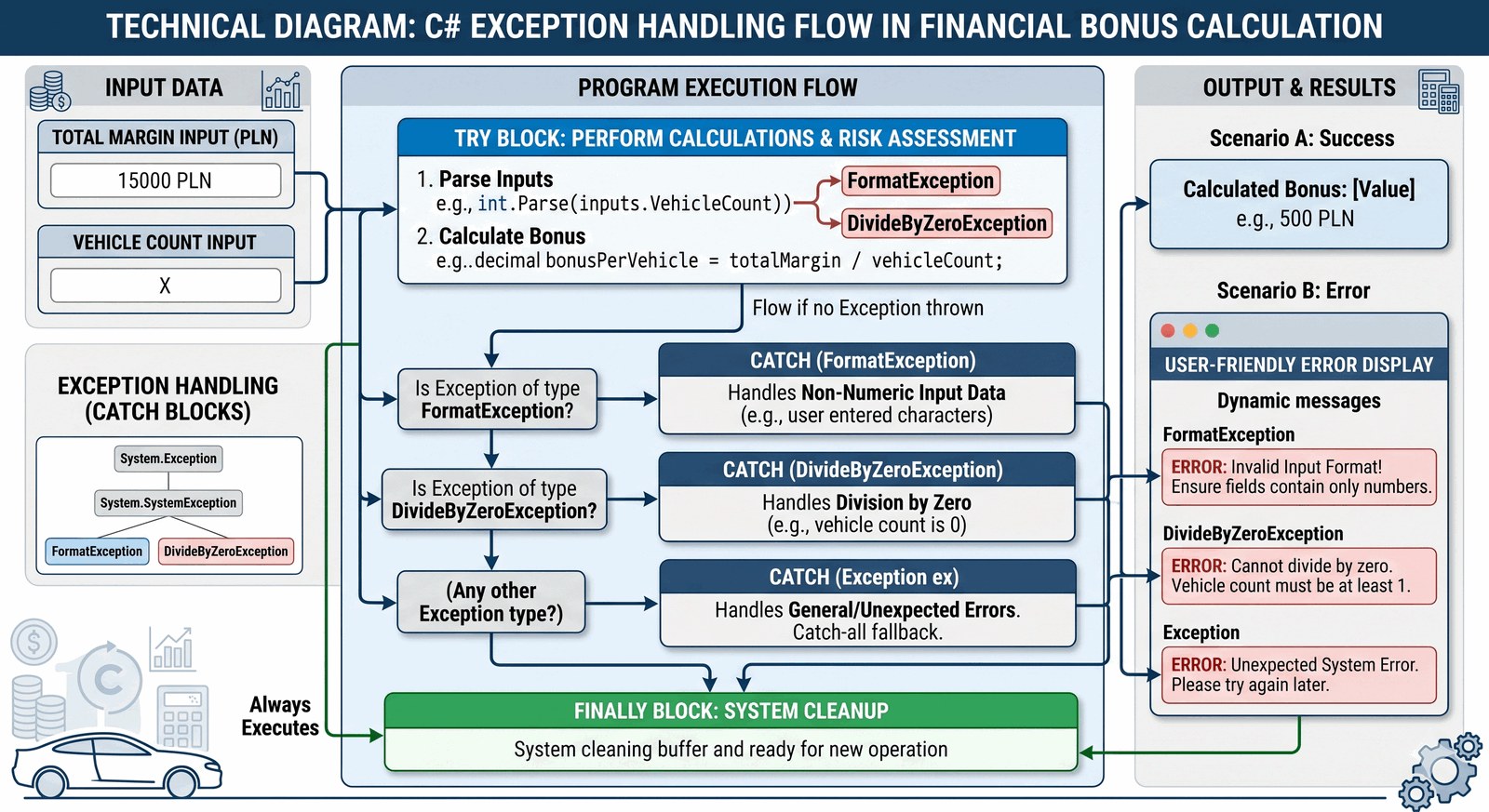
Implementacja mechanizmów odporności na błędy przy użyciu bloków try-catch-finally oraz walidacja danych wejściowych w sytuacjach krytycznych dla stabilności systemu finansowego.
Wewnętrzny system premiowy doradców Auto-Premium wylicza należną prowizję na podstawie marży uzyskanej ze sprzedaży luksusowego pojazdu. Jednak błędy ludzkie podczas wprowadzania danych, takie jak wpisanie tekstu zamiast kwoty lub próba obliczenia wskaźnika przy zerowej wartości bazowej (co prowadzi do błędu dzielenia przez zero), mogą spowodować nagłe zawieszenie się terminala finansowego. Jako programista musisz stworzyć bezpieczny kalkulator bonusów, który "owija" operacje matematyczne w bloki profesjonalnej obsługi wyjątków. Program ma za zadanie precyzyjnie przechwytywać błędy formatowania oraz błędy arytmetyczne, informować pracownika o naturze problemu w elegancki sposób i zapewniać, że aplikacja nie zamknie się niespodziewanie, tracąc wyniki poprzednich obliczeń. Wykorzystanie bloku finally do zasygnalizowania gotowości systemu do kolejnej próby obliczeniowej buduje standard niezawodności godny marki Premium. To podejście gwarantuje absolutną ciągłość pracy biznesowej i eliminuje frustrację personelu wynikającą z niestabilnego oprogramowania. Budujesz tutaj cyfrową tarczę, która chroni dane i czas Twoich współpracowników przed skutkami nieprzewidzianych sytuacji.
Wyjątek (Exception) to sygnał o wystąpieniu zdarzenia, które zakłóca normalny przepływ instrukcji w trakcie działania programu. Architektura try-catch pozwala na odseparowanie logiki biznesowej od logiki reakcji na błędy (tzw. handling). W bloku try umieszczamy instrukcje "wysokiego ryzyka", czyli takie, które zależą od danych z zewnątrz (np. int.Parse czy operacje dzielenia). Bloki catch muszą być ustawione w hierarchii od najbardziej specyficznych (np. FormatException) do najbardziej ogólnych (Exception), co pozwala na precyzyjne doprecyzowanie reakcji systemu. Blok finally jest kluczowy w inżynierii oprogramowania, ponieważ jego zawartość wykona się zawsze, niezależnie od tego, czy wystąpił błąd, czy też nie – jest to idealne miejsce na zamykanie strumieni danych lub resetowanie flag systemowych. Słowo kluczowe throw pozwala natomiast na ręczne rzucanie wyjątków, gdy warunki biznesowe (np. ujemna cena) nie są spełnione, mimo że składniowo kod jest poprawny. To zadanie uczy, jak zamienić "kruchy" kod w solidne, przemysłowe rozwiązanie odporne na błędy użytkownika.
class BonusCalculator
{
static void Main()
{
Console.WriteLine("=== BEZPIECZNY KALKULATOR PROWIZJI AUTO-PREMIUM ===");
try
{
Console.Write("Podaj kwotę marży (PLN): ");
int marza = int.Parse(Console.ReadLine());
Console.Write("Podaj liczbę sprzedanych aut: ");
int liczbaAut = int.Parse(Console.ReadLine());
// Potencjalne dzielenie przez zero
int sredniaProwizja = marza / liczbaAut;
Console.WriteLine($"[WYNIK] Średnia prowizja na auto: {sredniaProwizja:C}");
}
catch (FormatException)
{
Console.WriteLine("[BŁĄD] Wprowadzone dane nie są poprawnymi liczbami całkowitymi!");
}
catch (DivideByZeroException)
{
Console.WriteLine("[BŁĄD] Nie można wyliczyć średniej dla zera sprzedanych pojazdów.");
}
catch (Exception ex)
{
Console.WriteLine($"[KRYTYCZNY] Wystąpił nieoczekiwany błąd: {ex.Message}");
}
finally
{
Console.WriteLine("\n[SYSTEM] Czyszczenie bufora i gotowość do nowej operacji.");
}
}
}
Podaj kwotę marży (PLN): 15000
Podaj liczbę sprzedanych aut: zero
[BŁĄD] Wprowadzone dane nie są poprawnymi liczbami całkowitymi!
[SYSTEM] Czyszczenie bufora i gotowość do nowej operacji.
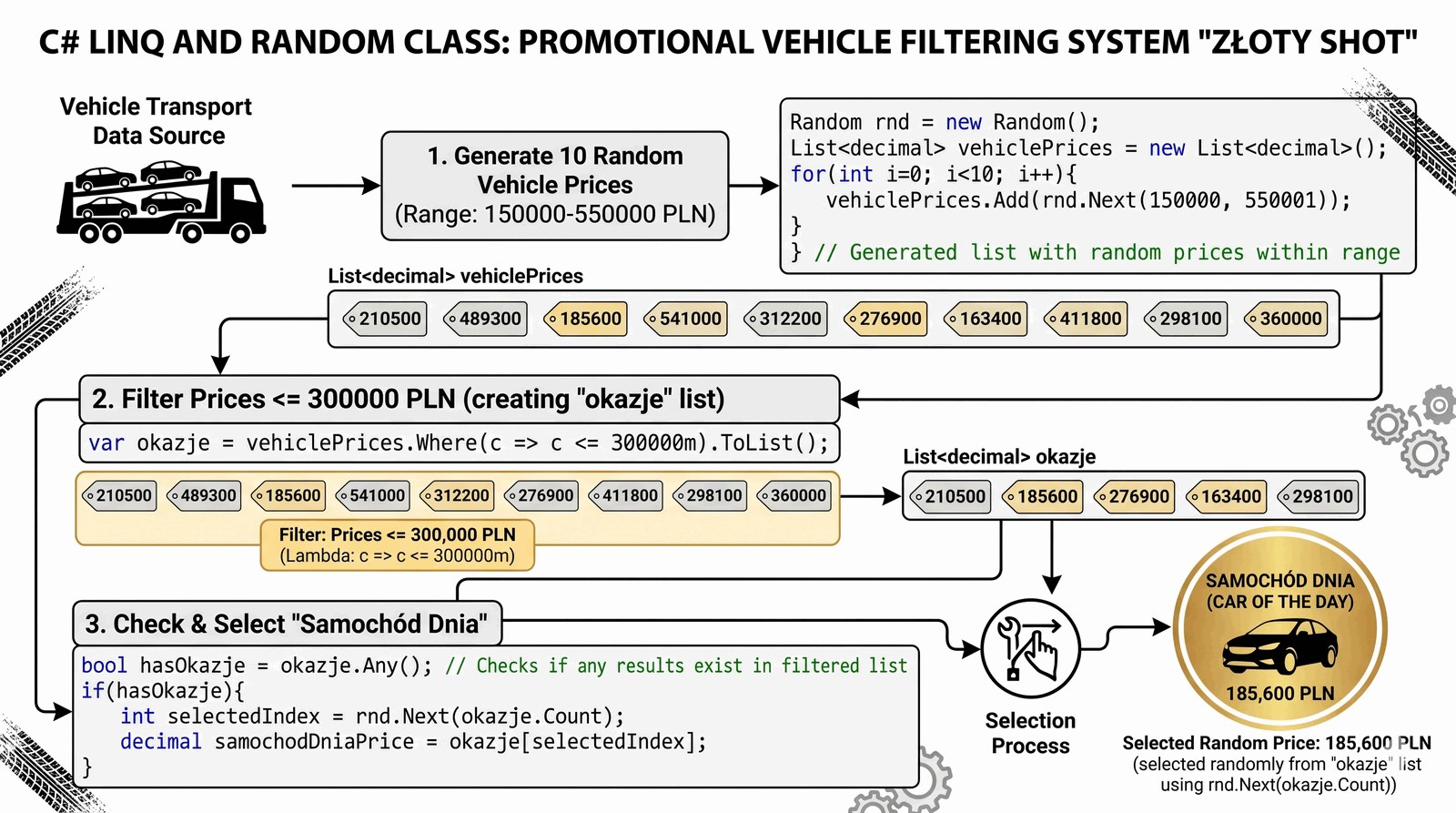
Poznanie nowoczesnych sposobów operowania na zbiorach danych przy użyciu technologii LINQ oraz symulacja danych losowych dla systemów marketingowych i promocyjnych.
Dział marketingu grupy Auto-Premium przygotowuje prestiżową akcję promocyjną o nazwie "Złoty Strzał", skierowaną do młodych inwestorów. System ma za zadanie automatycznie wygenerować listę 10 losowych cen aut znajdujących się aktualnie w transporcie, a następnie błyskawicznie wyłonić z nich te modele, których cena mieści się w "okazyjnym" przedziale do 300 000 PLN. Dodatkowo, aby uatrakcyjnić proces wyboru dla klienta, system musi wylosować jeden "Samochód Dnia" z tak przefiltrowanej listy wyników. Twoim zadaniem jest stworzenie silnika opartego na kolekcji List, wykorzystanie klasy Random do profesjonalnej symulacji rozpiętości cenowej (odzwierciedlającej realne warunki rynkowe) oraz zastosowanie deklaratywnego zapytania LINQ do błyskawicznego przesiania kolekcji. Takie podejście pozwala na tworzenie dynamicznych, spersonalizowanych ofert promocyjnych bez konieczności pisania wielu zagnieżdżonych pętli i instrukcji warunkowych. Budujesz tutaj inteligentny moduł analityczny, który wspiera procesy sprzedażowe grupy w czasie rzeczywistym, wykorzystując najnowsze wzorce projektowe języka C#. LINQ to potężne narzędzie, które sprawia, że Twój kod staje się bardziej zwięzły, czytelny i łatwiejszy w utrzymaniu. To zadanie stanowi klamrę spinającą Twoją wiedzę o kolekcjach, pokazując jak pracować z danymi na najwyższym stopniu abstrakcji.
Technologia LINQ (Language Integrated Query) to zestaw metod rozszerzających w C#, które umożliwiają wykonywanie zaawansowanych operacji na kolekcjach (takich jak filtrowanie, sortowanie czy grupowanie) w sposób deklaratywny, niemal identyczny jak w zapytaniach SQL. Metoda Where() przyjmuje tzw. wyrażenie lambda (np. c => c < 300000m), które definiuje warunek, jaki musi spełnić każdy element, aby trafić do wyniku. Dzięki temu kod "opisuje co ma być zrobione", a nie "jak ma być zrobione krok po kroku", co drastycznie podnosi jego jakość i czytelność. Klasa Random jest generatorem liczb pseudolosowych; dobrą praktyką jest tworzenie jej instancji tylko raz, co zapobiega generowaniu tych samych sekwencji w krótkich odstępach czasu (tzw. seeding problem). Metoda Next(min, max) zwraca losową liczbę całkowitą, którą w systemach finansowych rzutujemy na decimal dla zachowania precyzji. Pobranie losowego elementu z listy wyników następuje poprzez odwołanie się do indeksu wylosowanego z zakresu od zera do Count-1. Połączenie LINQ i elementów losowości to standardowy wzorzec w budowie nowoczesnych systemów rekomendacyjnych, gier i narzędzi do analizy typu Big Data.
using System.Collections.Generic;
using System.Linq; // Wymagane dla LINQ
class PromoEngine
{
static void Main()
{
Random rnd = new Random();
List<decimal> cenyTransportu = new List<decimal>();
// Generowanie 10 losowych cen aut od 150k do 549 999
for (int i = 0; i < 10; i++)
{
cenyTransportu.Add(rnd.Next(150000, 550000));
}
Console.WriteLine("=== SYSTEM PROMOCYJNY AUTO-PREMIUM: 'ZŁOTY STRZAŁ' ===");
Console.WriteLine("Analiza aut w transporcie...");
// Filtrowanie LINQ: wybierz auta do 300 000 PLN
var okazje = cenyTransportu.Where(c => c <= 300000).ToList();
string formaAuta = okazje.Count == 1 ? "auto" : (okazje.Count % 10 >= 2 && okazje.Count % 10 <= 4 && (okazje.Count % 100 < 10 || okazje.Count % 100 >= 20)) ? "auta" : "aut";
Console.WriteLine($"Znaleziono {okazje.Count} {formaAuta} spełniających kryteria cenowe.");
if (okazje.Any()) // Sprawdzenie czy lista nie jest pusta za pomocą LINQ
{
int index = rnd.Next(okazje.Count);
decimal samochodDnia = okazje[index];
Console.WriteLine("\n[PROMOCJA DLA CIEBIE]");
Console.WriteLine($"SAMOCHÓD DNIA W CENIE: {samochodDnia:C2}");
}
else
{
Console.WriteLine("Obecnie brak aut w wybranym przedziale cenowym.");
}
}
}
Analiza aut w transporcie...
Znaleziono 4 auta spełniających kryteria cenowe.
[PROMOCJA DLA CIEBIE]
SAMOCHÓD DNIA W CENIE: 245 600,00 zł